def hello_world (name):
"""Greets the indicated person and the world in general."""
print (f"Hello {name} and world")
hello_world ("Jaume")Hello Jaume and worldExploring AML through Hello World components.
Note: this post is just a draft in progress. As of now, it consists of a collection of random notes.
The purpose of this tutorial is to show how to incrementally build a pipeline from simple and debuggable “Hello World” components. In order to run this at home, you may find it useful to create a free Azure ML subscription as described in the how-to guide I have here
In this section, we will write our code in a notebook and make sure it works well. Then, we will convert it to a script and run it from the terminal. Finally, we will add some logs with MLFlow.
Although not required, as a very first step we can create a environment and kernel following the tutorial in https://learn.microsoft.com/en-gb/azure/machine-learning/tutorial-cloud-workstation?view=azureml-api-2
Following the previous tutorial, create a notebook and type the following hello world code:
def hello_world (name):
"""Greets the indicated person and the world in general."""
print (f"Hello {name} and world")
hello_world ("Jaume")Hello Jaume and worldFantastic, the code works ;-). Now, let’s convert it to a script that can be run from terminal. The tutorial above explains how to convert the notebook to a python file. In our case, we will first add an argument parser and then write it to file using the magic cell %%writefile
%%writefile hello_world_core.py
import argparse
def hello_world (name):
"""Greets the indicated person and the world in general."""
print (f"Hello {name} and world")
def parse_args ():
"""Parses input arguments"""
parser = argparse.ArgumentParser()
parser.add_argument("--name", type=str, help="person to greet")
args = parser.parse_args()
return args
def main():
"""Main function of the script."""
args = parse_args ()
hello_world (args.name)
if __name__ == "__main__":
main()Writing hello_world_core.pyBad pipe message: %s [b'\x80\xb8\xc2\x0e\x1b\xcd4\xe90\x12O\x89\xff4\x0b\xbf;\xab \xb6*\xd3\xab\x91\xb6\x87\xe82s\x1fIv\xd3\x172\xa6\x11\xb2w\xff\xf2\x02L\xbf_\xc1\t\x1dn\xdc\x0f\x00\x08\x13\x02\x13\x03\x13\x01\x00\xff\x01\x00\x00\x8f\x00\x00\x00\x0e\x00\x0c\x00\x00\t127.0.0.1\x00\x0b\x00\x04\x03\x00\x01\x02\x00\n\x00\x0c\x00\n\x00\x1d\x00\x17\x00\x1e\x00\x19\x00\x18\x00#\x00\x00\x00\x16\x00\x00\x00\x17\x00\x00\x00\r\x00\x1e\x00\x1c\x04\x03\x05\x03\x06\x03\x08\x07\x08\x08\x08\t\x08\n\x08\x0b\x08\x04\x08\x05\x08\x06\x04\x01\x05\x01\x06\x01\x00+\x00\x03\x02\x03\x04\x00-\x00\x02']
Bad pipe message: %s [b'4\xf9%\x9at\xbe\x08\x03\x06\xf5.E\xe9\xd7\xb3\xa1Z\x8d ']
Bad pipe message: %s [b'\x0c5\x85\xf5Z']
Bad pipe message: %s [b'\xe3\x18^', b'\x9cOo\xfe*\xa90\xa3\xf8\xfa#\x8d\x0b\x00\x00\xa2\xc0\x14\xc0\n\x009\x008\x007\x006\x00\x88\x00\x87\x00\x86\x00\x85\xc0\x19\x00:\x00\x89\xc0\x0f\xc0\x05\x005\x00\x84\xc0\x13\xc0\t\x003\x002\x001\x000\x00\x9a\x00\x99\x00\x98\x00\x97\x00E\x00D\x00C\x00B\xc0\x18\x004\x00\x9b\x00F\xc0\x0e\xc0\x04\x00/\x00\x96\x00A\x00\x07\xc0\x11\xc0\x07\xc0\x16\x00\x18\xc0\x0c\xc0\x02\x00\x05\x00\x04\xc0\x12\xc0\x08\x00\x16\x00\x13\x00\x10\x00\r\xc0\x17\x00\x1b\xc0\r\xc0\x03\x00\n\x00\x15\x00\x12\x00\x0f\x00\x0c\x00\x1a\x00\t\x00\x14\x00\x11\x00\x19\x00\x08\x00\x06\x00\x17\x00\x03\xc0\x10\xc0\x06\xc0\x15\xc0\x0b\xc0\x01\x00\x02\x00\x01\x00\xff\x02\x01\x00\x00C\x00\x00\x00\x0e\x00\x0c\x00\x00\t127.0.0.1\x00\x0b\x00\x04\x03\x00\x01\x02\x00\n\x00\x1c\x00\x1a\x00\x17\x00\x19\x00\x1c\x00\x1b\x00\x18\x00\x1a\x00\x16\x00\x0e\x00\r']
Bad pipe message: %s [b"\x85c}\xe4\x85\xb5*i\xf3vog\x0b\x16\\\xdd\x9e\x0e\x00\x00\x86\xc00\xc0,\xc0(\xc0$\xc0\x14\xc0\n\x00\xa5\x00\xa3\x00\xa1\x00\x9f\x00k\x00j\x00i\x00h\x009\x008\x007\x006\xc02\xc0.\xc0*\xc0&\xc0\x0f\xc0\x05\x00\x9d\x00=\x005\xc0/\xc0+\xc0'\xc0#\xc0\x13\xc0\t\x00\xa4\x00\xa2\x00\xa0\x00\x9e\x00g\x00@\x00?\x00>\x003\x00", b'1\x000\xc01\xc0-\xc0)\xc0%\xc0\x0e\xc0\x04\x00\x9c\x00<\x00/\x00\x9a\x00\x99\x00\x98\x00\x97\x00\x96\x00\x07\xc0\x11\xc0\x07\xc0\x0c\xc0\x02\x00\x05\x00\x04\x00\xff\x02\x01']
Bad pipe message: %s [b"\xf3\x03\x81E\x16\x17\x18\x1e0(\xa5\x94\x96\x98\x0cw\xd6\xe3\x00\x00\xf4\xc00\xc0,\xc0(\xc0$\xc0\x14\xc0\n\x00\xa5\x00\xa3\x00\xa1\x00\x9f\x00k\x00j\x00i\x00h\x009\x008\x007\x006\x00\x88\x00\x87\x00\x86\x00\x85\xc0\x19\x00\xa7\x00m\x00:\x00\x89\xc02\xc0.\xc0*\xc0&\xc0\x0f\xc0\x05\x00\x9d\x00=\x005\x00\x84\xc0/\xc0+\xc0'\xc0#\xc0\x13\xc0\t\x00\xa4\x00\xa2\x00\xa0\x00\x9e\x00g\x00@\x00?\x00>\x003\x002\x001\x000\x00\x9a\x00\x99\x00\x98\x00\x97\x00E\x00D\x00C\x00B\xc0\x18\x00\xa6\x00l\x004\x00\x9b\x00F\xc01\xc0-\xc0)\xc0%\xc0\x0e\xc0\x04\x00\x9c\x00<\x00", b'\x96\x00A\x00\x07\xc0\x11\xc0\x07\xc0\x16\x00\x18\xc0\x0c\xc0\x02\x00\x05\x00\x04\xc0\x12\xc0\x08\x00\x16\x00\x13\x00\x10\x00\r\xc0\x17\x00\x1b\xc0\r\xc0\x03\x00\n\x00\x15\x00']
Bad pipe message: %s [b'\x0f\x00\x0c\x00\x1a\x00\t\x00\x14\x00\x11\x00\x19\x00\x08\x00\x06']Now, we can open up a terminal, as illustrated in the tutorial above, cd to the folder where the script is and run it:
cd Users/<my_user>/hello_world
python hello_world_core.py --name Jaume%%writefile hello_world_with_logs.py
import mlflow
from hello_world_core import hello_world, parse_args
def start_logging (args):
# set name for logging
mlflow.set_experiment("Hello World with logging")
mlflow.start_run()
mlflow.log_param ("name to log", args.name)
def finish_logging ():
mlflow.end_run ()
def main():
"""Main function of the script."""
args = parse_args ()
start_logging (args)
hello_world (args.name)
finish_logging ()
if __name__ == "__main__":
main()Overwriting hello_world_with_logs.pyLet’s run it and see:
python hello_world_with_logs.py --name PeterHere is the newly created job:
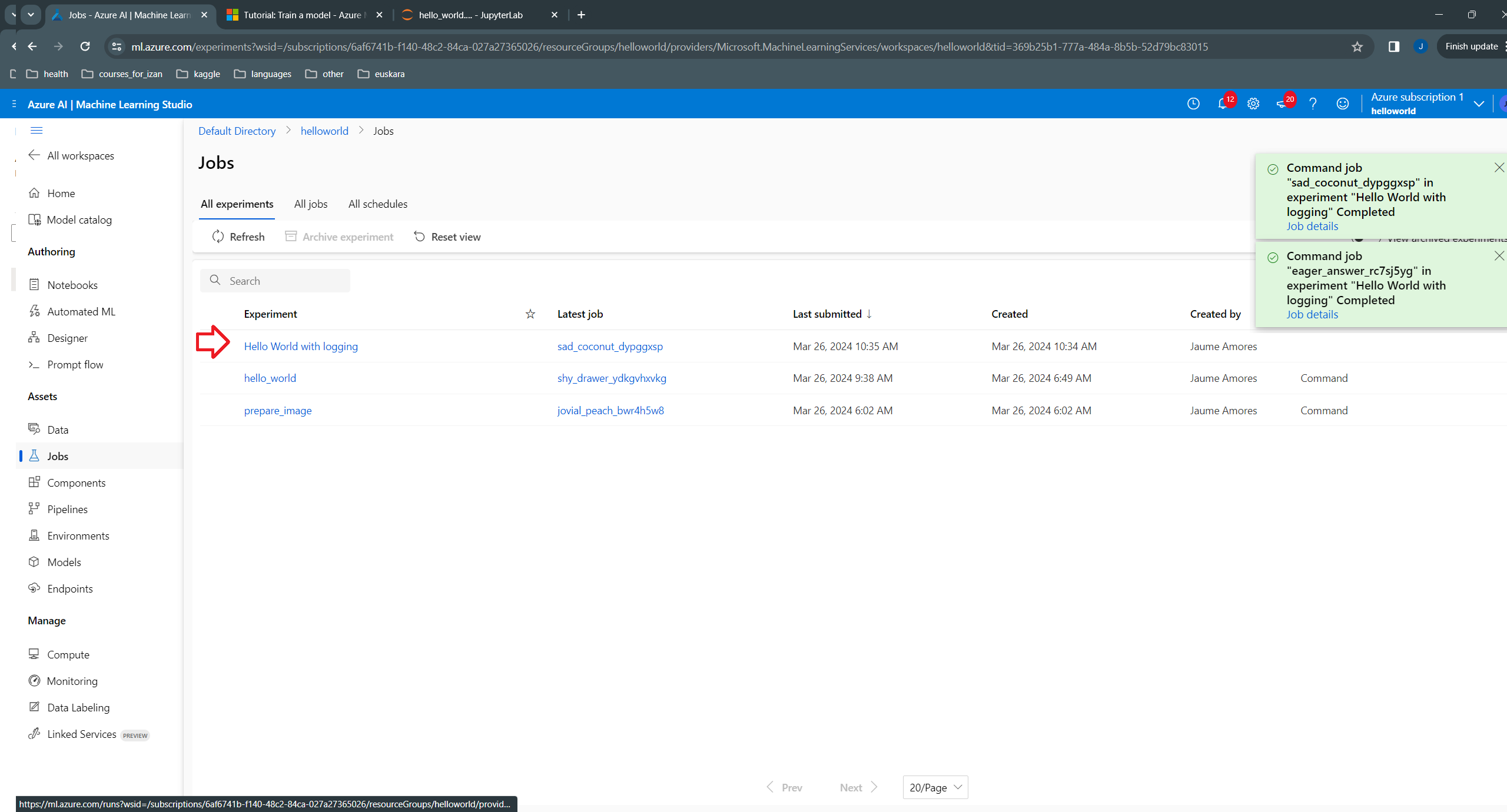
And the name passed as argument:
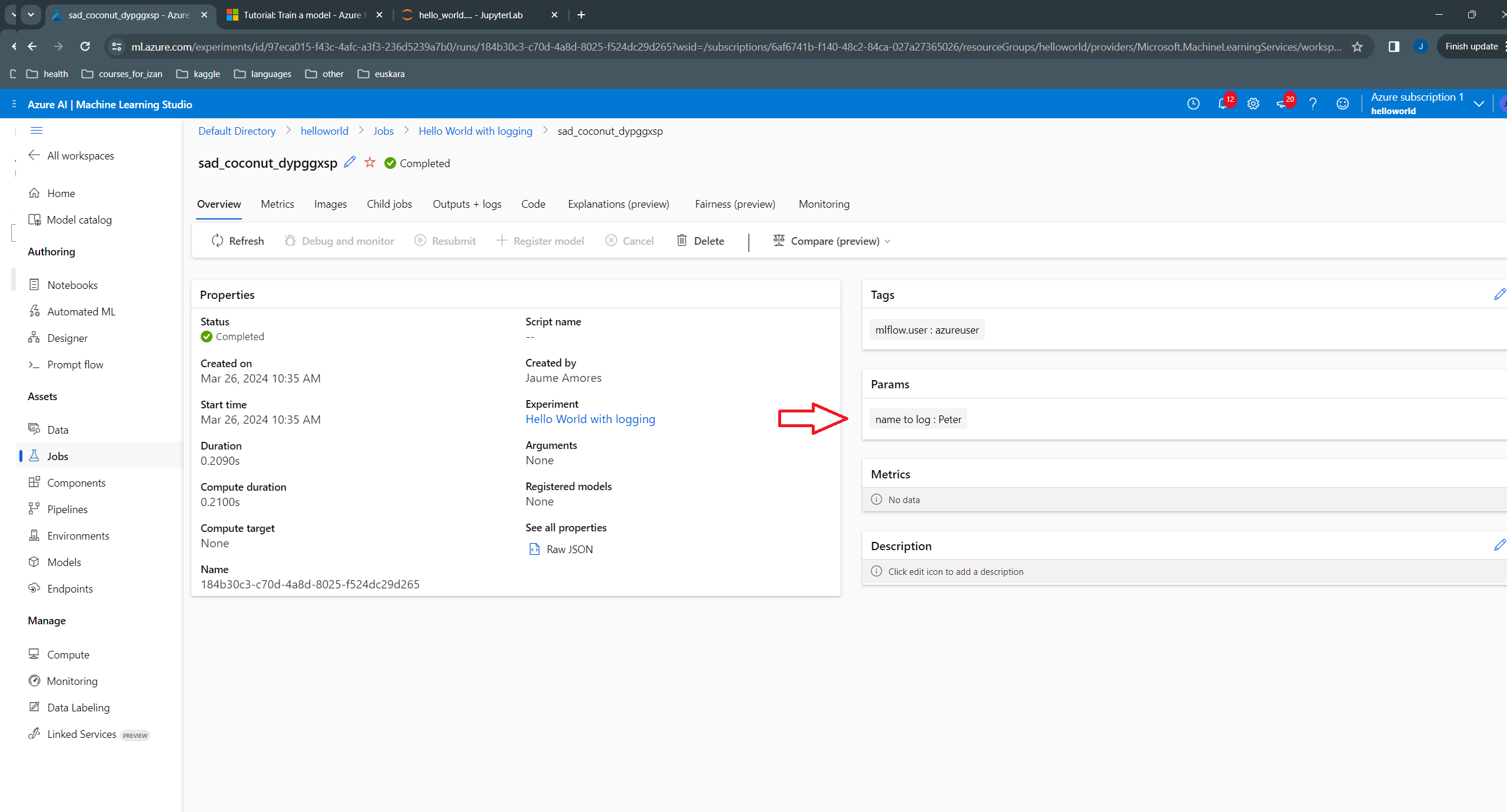
We start by getting a connection to our Azure ML (AML for short) workspace. We use here a simple connection mechanism that doesn’t require writting your subscription, resource group and workspace details:
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
# authenticate
credential = DefaultAzureCredential()
# Get a handle to the workspace
ml_client = MLClient.from_config (
credential=credential
)Found the config file in: /config.jsonWe now convert the previous script into a job that can be run from the UI.
# Standard imports
import os
# Third-party imports
import pandas as pd
# AML imports
from azure.ai.ml import (
command,
dsl,
Input,
Output,
MLClient
)
from azure.identity import DefaultAzureCredentialFor the remaining part of this tutorial, we will be needing an ml_client handle. This will allow us to create and use resources from our workspace. The simplest way to get such handle is with the following code:
# authenticate
credential = DefaultAzureCredential()
# Get a handle to the workspace
ml_client = MLClient.from_config (
credential=credential
)Found the config file in: /config.jsonWe specify a job using the command decorator:
job = command(
inputs=dict(
name="Jaume", # default value of our parameter
),
code=f"./", # location of source code: in this case, the root folder
command="python hello_world_core.py --name ${{inputs.name}}",
environment="AzureML-sklearn-1.0-ubuntu20.04-py38-cpu@latest",
display_name="Simplest Hello World",
)Note: we indicate as environment “AzureML-sklearn-1.0-ubuntu20.04-py38-cpu@latest”, which actually contains more libraries than we need, such as sklearn. Simpler environments to use can be found in the “Environments” section of the workspace.
… and submit it using create_or_update from ml_client:
ml_client.create_or_update(job)Class AutoDeleteSettingSchema: This is an experimental class, and may change at any time. Please see https://aka.ms/azuremlexperimental for more information.
Class AutoDeleteConditionSchema: This is an experimental class, and may change at any time. Please see https://aka.ms/azuremlexperimental for more information.
Class BaseAutoDeleteSettingSchema: This is an experimental class, and may change at any time. Please see https://aka.ms/azuremlexperimental for more information.
Class IntellectualPropertySchema: This is an experimental class, and may change at any time. Please see https://aka.ms/azuremlexperimental for more information.
Class ProtectionLevelSchema: This is an experimental class, and may change at any time. Please see https://aka.ms/azuremlexperimental for more information.
Class BaseIntellectualPropertySchema: This is an experimental class, and may change at any time. Please see https://aka.ms/azuremlexperimental for more information.
Uploading hello_world (8.59 MBs): 100%|██████████| 8591281/8591281 [00:00<00:00, 40584539.30it/s]
| Experiment | Name | Type | Status | Details Page |
|---|---|---|---|---|
| hello_world | clever_spade_sq4jwcg67r | command | Starting | Link to Azure Machine Learning studio |
In the link that appears, we can see the status of the job, which initially is “Queued”. We need to wait until it is completed (and refresh the page to see this). Once it is completed, we can look at the logs:
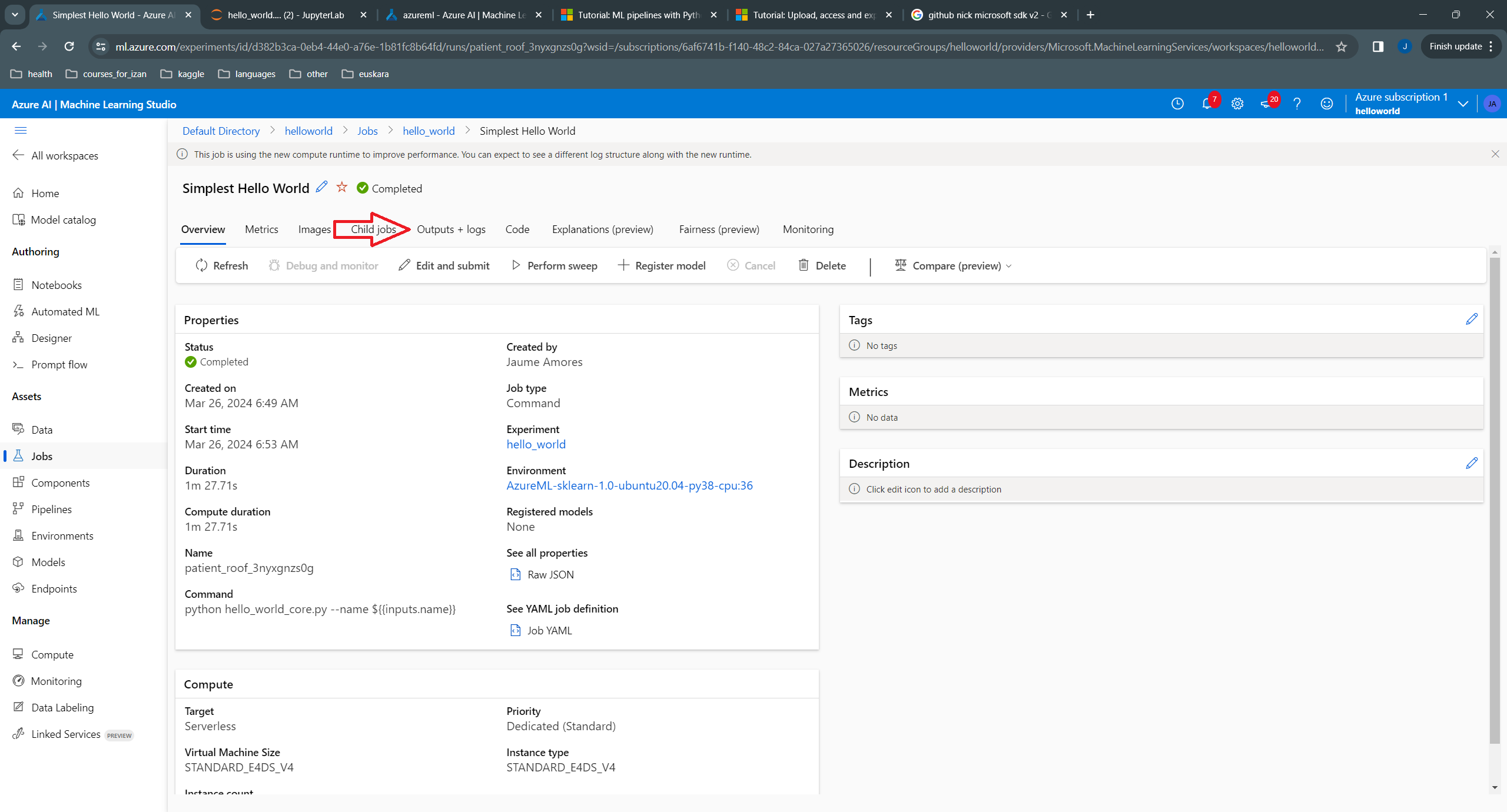
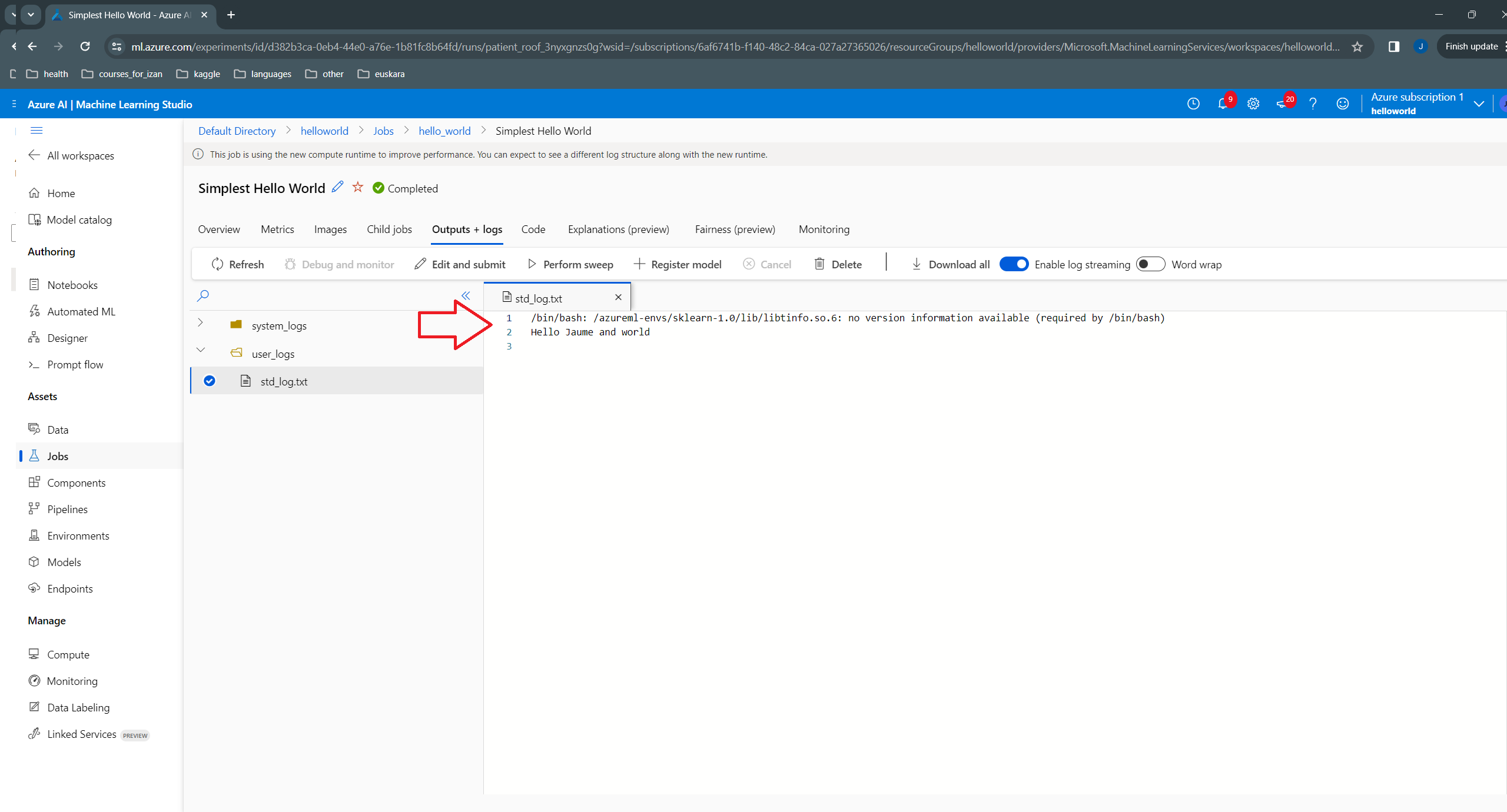
In the logs, we can see the messages printed in console:
Above, we indicated a default value for the input argument name. It would be good to be able to submit jobs with different values for that argument. One way to do that is:
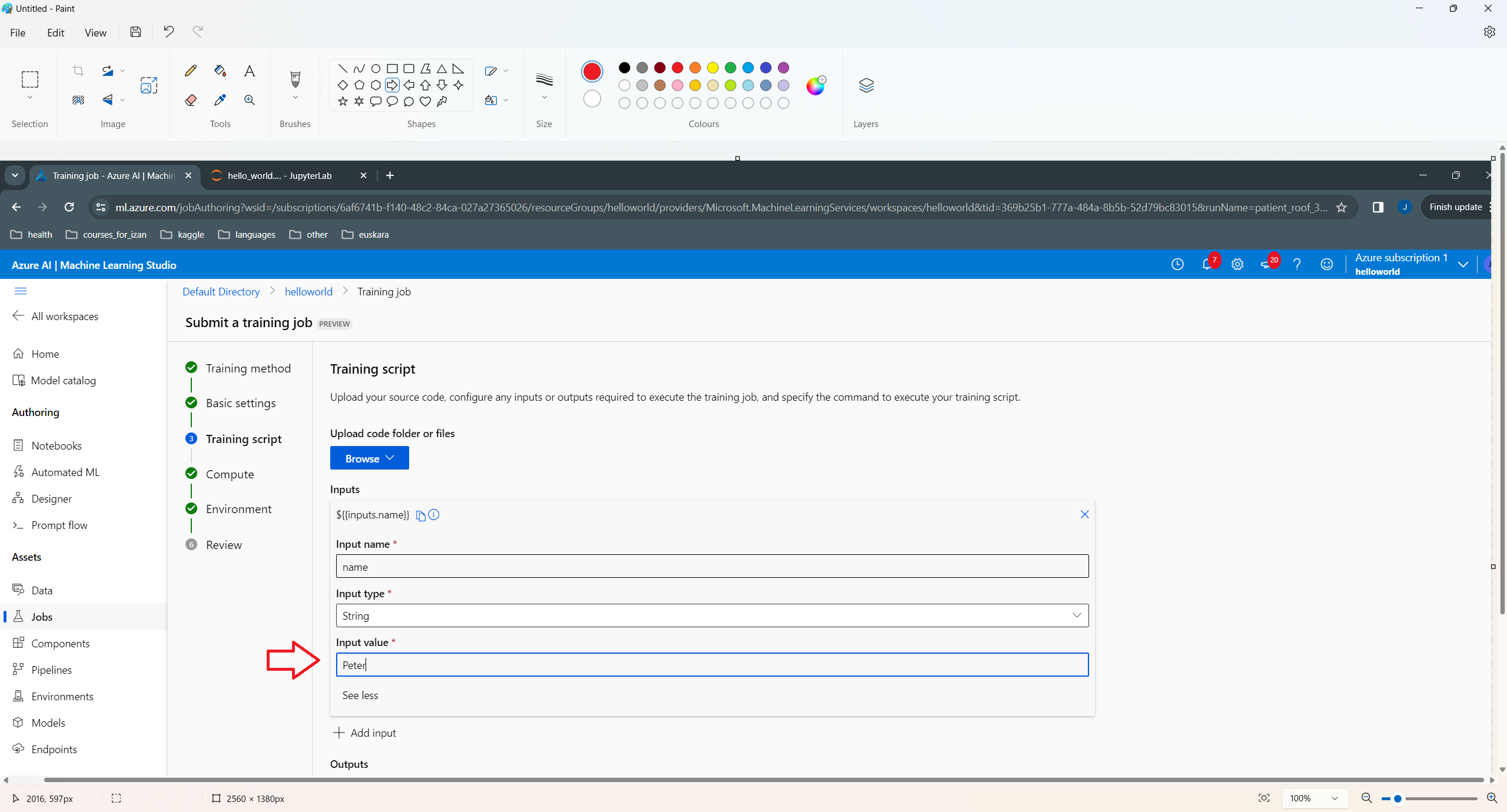
Hit Next several times and then Submit.
If we go to the jobs section of the workspace, and enter again our job (“helloworld”), we can see that a new job has been submitted:
In its Overview tab, under “See all properties”, we can inspect the json file:
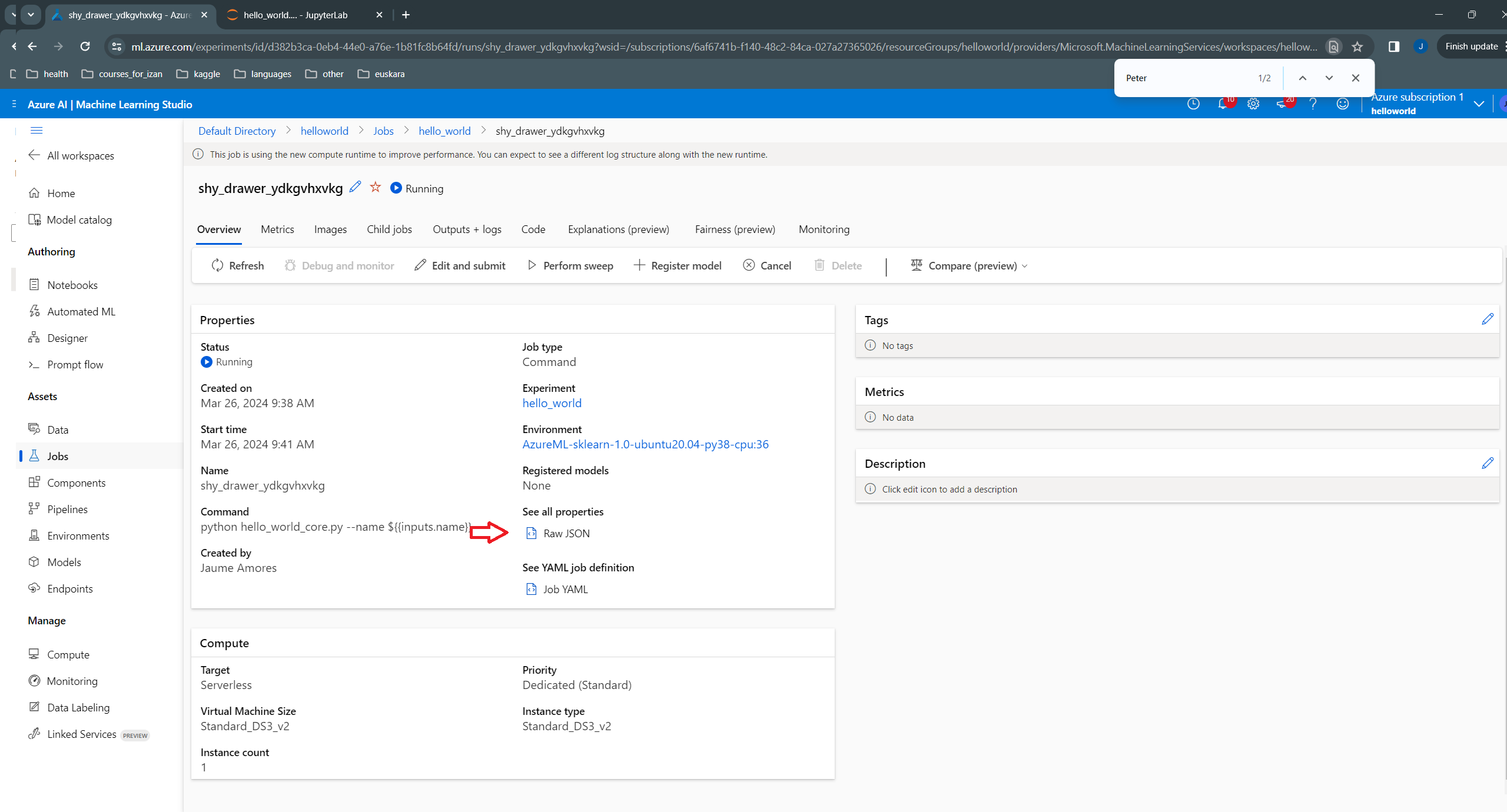
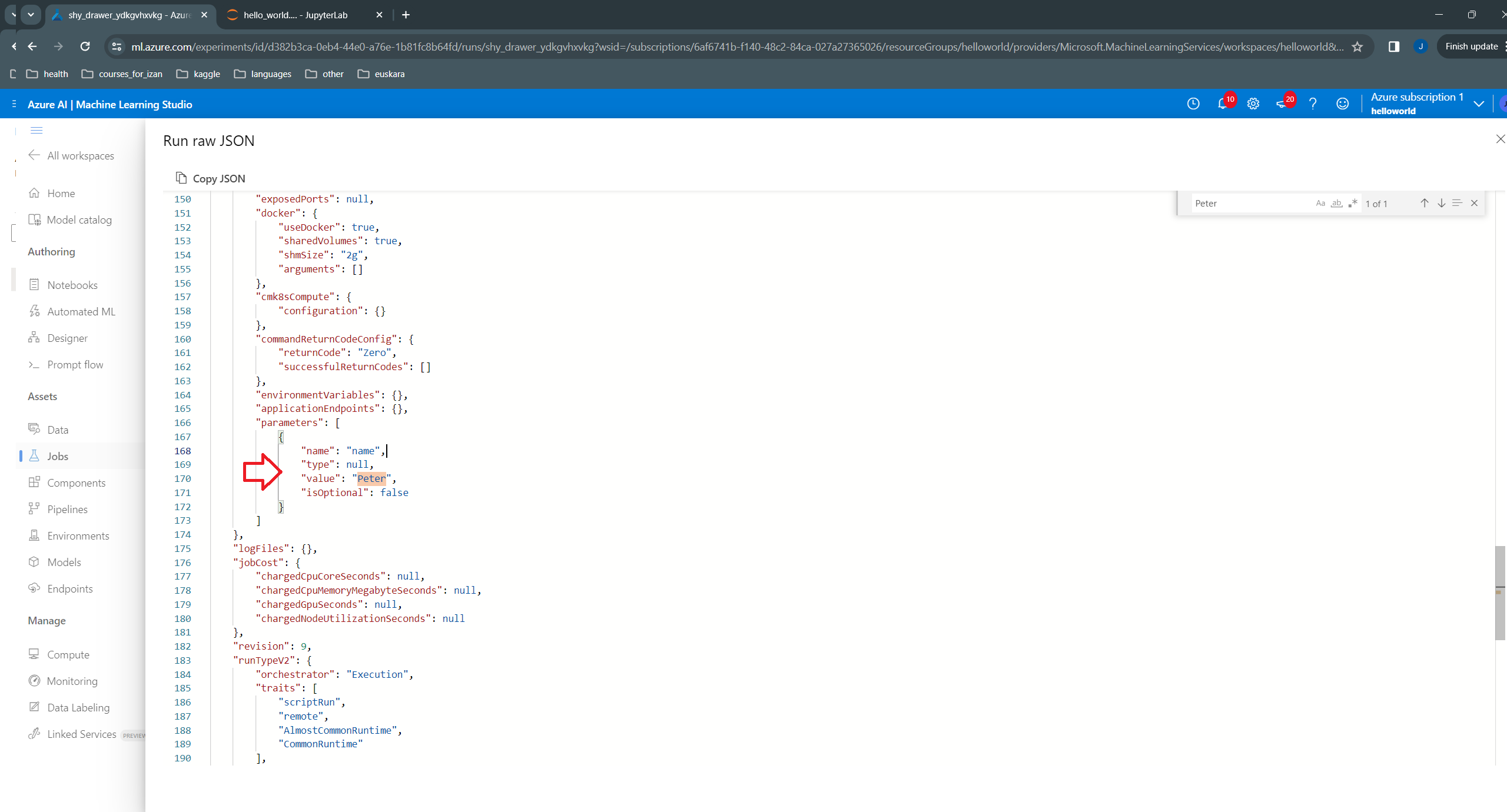
… and see that the new value (Peter) is used in its “parameters” dictionary:
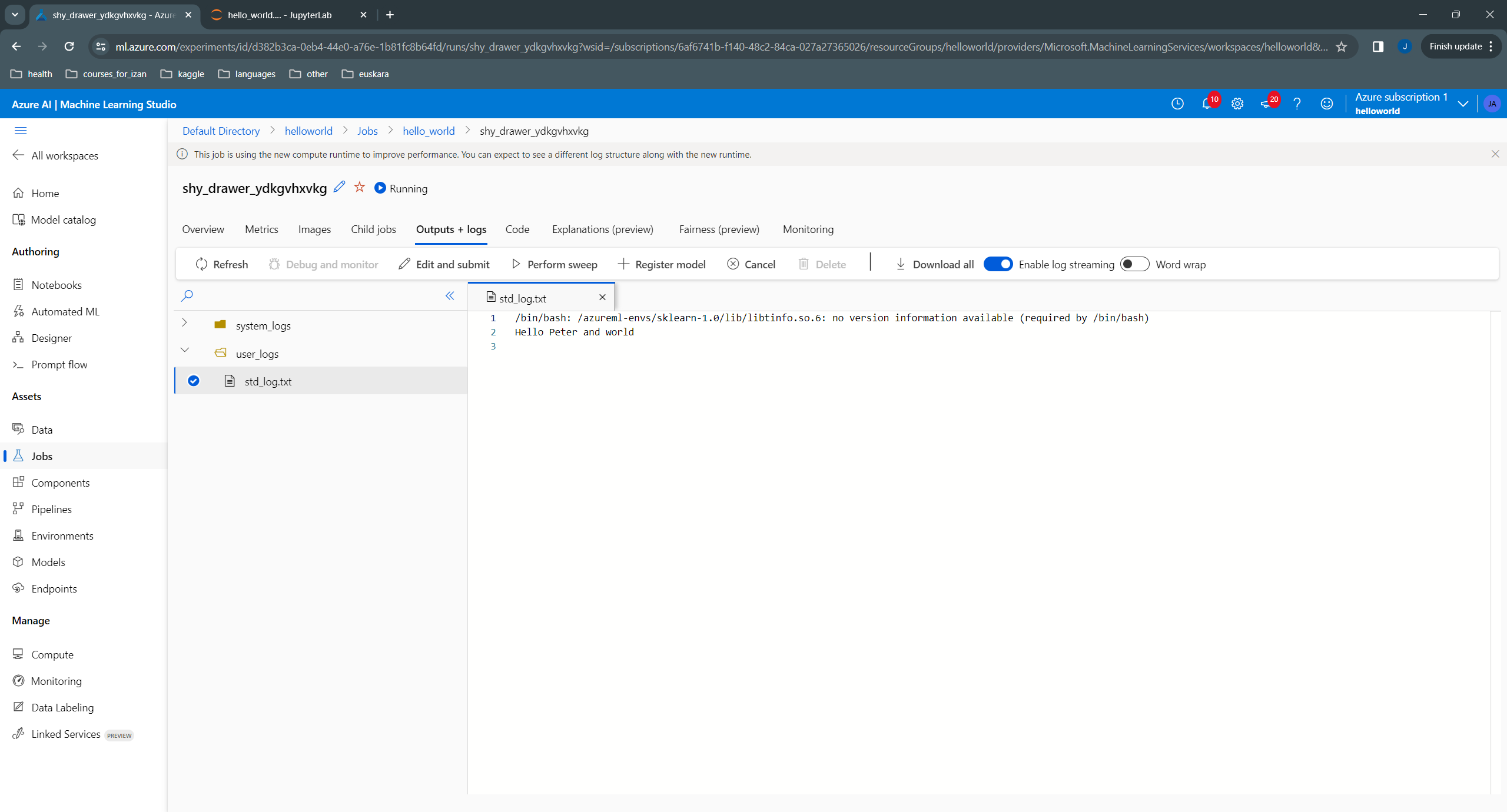
The std_log.txt for this job shows the new message with Peter:
hello_world_component = ml_client.create_or_update(job.component)Uploading hello_world (8.58 MBs): 100%|██████████| 8578531/8578531 [00:00<00:00, 21700197.27it/s]
# the dsl decorator tells the sdk that we are defining an Azure Machine Learning pipeline
@dsl.pipeline(
compute="serverless", # "serverless" value runs pipeline on serverless compute
description="E2E hello world pipeline",
)
def hello_world_pipeline(
pipeline_job_input: str,
):
"""
Hello World pipeline
Parameters
----------
pipeline_job_input: str
Input to pipeline, here name of person to greed.
"""
# using data_prep_function like a python call with its own inputs
hello_world_job = hello_world_component(
name=pipeline_job_input,
)# Let's instantiate the pipeline with the parameters of our choice
pipeline = hello_world_pipeline(
pipeline_job_input="David",
)pipeline_job = ml_client.jobs.create_or_update(
pipeline,
# Project's name
experiment_name="e2e_registered_components",
)
ml_client.jobs.stream(pipeline_job.name)Class AutoDeleteSettingSchema: This is an experimental class, and may change at any time. Please see https://aka.ms/azuremlexperimental for more information.
Class AutoDeleteConditionSchema: This is an experimental class, and may change at any time. Please see https://aka.ms/azuremlexperimental for more information.
Class BaseAutoDeleteSettingSchema: This is an experimental class, and may change at any time. Please see https://aka.ms/azuremlexperimental for more information.
Class IntellectualPropertySchema: This is an experimental class, and may change at any time. Please see https://aka.ms/azuremlexperimental for more information.
Class ProtectionLevelSchema: This is an experimental class, and may change at any time. Please see https://aka.ms/azuremlexperimental for more information.
Class BaseIntellectualPropertySchema: This is an experimental class, and may change at any time. Please see https://aka.ms/azuremlexperimental for more information.RunId: shy_cabbage_xb9vv4fswl
Web View: https://ml.azure.com/runs/shy_cabbage_xb9vv4fswl?wsid=/subscriptions/6af6741b-f140-48c2-84ca-027a27365026/resourcegroups/helloworld/workspaces/helloworld
Streaming logs/azureml/executionlogs.txt
========================================
[2024-03-26 14:08:19Z] Submitting 1 runs, first five are: 605cf9a7:d9904e2d-3ecb-4ddc-a04d-e2fed4facfe6
[2024-03-26 14:12:40Z] Completing processing run id d9904e2d-3ecb-4ddc-a04d-e2fed4facfe6.
Execution Summary
=================
RunId: shy_cabbage_xb9vv4fswl
Web View: https://ml.azure.com/runs/shy_cabbage_xb9vv4fswl?wsid=/subscriptions/6af6741b-f140-48c2-84ca-027a27365026/resourcegroups/helloworld/workspaces/helloworld
job = command(
inputs=dict(
name=Input (type="string"),
),
code=f"./", # location of source code: in this case, the root folder
command="python hello_world_core.py --name ${{inputs.name}}",
environment="AzureML-sklearn-1.0-ubuntu20.04-py38-cpu@latest",
display_name="Hello World witn Input",
)
hello_world_component = ml_client.create_or_update(job.component)Uploading hello_world (8.59 MBs): 100%|██████████| 8589758/8589758 [00:00<00:00, 24178345.78it/s]
# the dsl decorator tells the sdk that we are defining an Azure Machine Learning pipeline
from azure.ai.ml import dsl
@dsl.pipeline(
compute="serverless", # "serverless" value runs pipeline on serverless compute
description="E2E hello world pipeline with input",
)
def hello_world_pipeline(
pipeline_job_input: str,
):
"""
Hello World pipeline
Parameters
----------
pipeline_job_input: str
Input to pipeline, here name of person to greed.
"""
# using data_prep_function like a python call with its own inputs
hello_world_job = hello_world_component(
name=pipeline_job_input,
)pipeline = hello_world_pipeline(
pipeline_job_input="Joseph",
)
pipeline_job = ml_client.jobs.create_or_update(
pipeline,
# Project's name
experiment_name="e2e_hello_world_with_input",
)
ml_client.jobs.stream(pipeline_job.name)RunId: olive_plastic_gvnjy01b5s
Web View: https://ml.azure.com/runs/olive_plastic_gvnjy01b5s?wsid=/subscriptions/6af6741b-f140-48c2-84ca-027a27365026/resourcegroups/helloworld/workspaces/helloworld
Streaming logs/azureml/executionlogs.txt
========================================
[2024-03-26 14:38:43Z] Submitting 1 runs, first five are: cd1599c4:ce24c41e-946d-48cd-99b2-70ebde3befb2
[2024-03-26 14:44:58Z] Completing processing run id ce24c41e-946d-48cd-99b2-70ebde3befb2.
Execution Summary
=================
RunId: olive_plastic_gvnjy01b5s
Web View: https://ml.azure.com/runs/olive_plastic_gvnjy01b5s?wsid=/subscriptions/6af6741b-f140-48c2-84ca-027a27365026/resourcegroups/helloworld/workspaces/helloworld
Notes about Input:
job = command(
inputs=dict(
file_name=Input (type="uri_file"),
),
...
)
pipeline = hello_world_pipeline(
pipeline_job_input=Input(path="/path/to/file"),
)job = command(
inputs=dict(
name=Input (type="string"),
),
...
)
pipeline = hello_world_pipeline(
pipeline_job_input="Mary",
)# Component definition and registration
job = command(
inputs=dict(
name=Input (type="uri_file"),
),
code=f"./", # location of source code: in this case, the root folder
command="python hello_world_core.py --name ${{inputs.name}}",
environment="hello-world",
display_name="Hello World with uri_file",
)
hello_world_component = ml_client.create_or_update(job.component)
# Pipeline definition and registration
@dsl.pipeline(
compute="serverless", # "serverless" value runs pipeline on serverless compute
description="E2E hello world pipeline with input",
)
def hello_world_pipeline(
pipeline_job_input: str,
):
"""
Hello World pipeline
Parameters
----------
pipeline_job_data_input: str
Input to pipeline, here path to file.
"""
# using data_prep_function like a python call with its own inputs
hello_world_job = hello_world_component(
name=pipeline_job_input,
)
pipeline = hello_world_pipeline(
pipeline_job_input=Input(type="uri_file", path="./hello_world_core.py"),
)
pipeline_job = ml_client.jobs.create_or_update(
pipeline,
# Project's name
experiment_name="e2e_hello_world_with_uri_file",
)
# Pipeline running
ml_client.jobs.stream(pipeline_job.name)Uploading hello_world (8.59 MBs): 100%|██████████| 8588206/8588206 [00:00<00:00, 24482901.98it/s]
Uploading hello_world_core.py (< 1 MB): 0.00B [00:00, ?B/s] (< 1 MB): 100%|██████████| 514/514 [00:00<00:00, 12.0kB/s]
RunId: great_tail_pw48pry0lj
Web View: https://ml.azure.com/runs/great_tail_pw48pry0lj?wsid=/subscriptions/6af6741b-f140-48c2-84ca-027a27365026/resourcegroups/helloworld/workspaces/helloworld
Streaming logs/azureml/executionlogs.txt
========================================
[2024-03-26 15:06:11Z] Submitting 1 runs, first five are: a08118c5:2099b6ad-fb3a-4cac-9557-c8cf355b8b1b
[2024-03-26 15:11:50Z] Completing processing run id 2099b6ad-fb3a-4cac-9557-c8cf355b8b1b.
Execution Summary
=================
RunId: great_tail_pw48pry0lj
Web View: https://ml.azure.com/runs/great_tail_pw48pry0lj?wsid=/subscriptions/6af6741b-f140-48c2-84ca-027a27365026/resourcegroups/helloworld/workspaces/helloworld
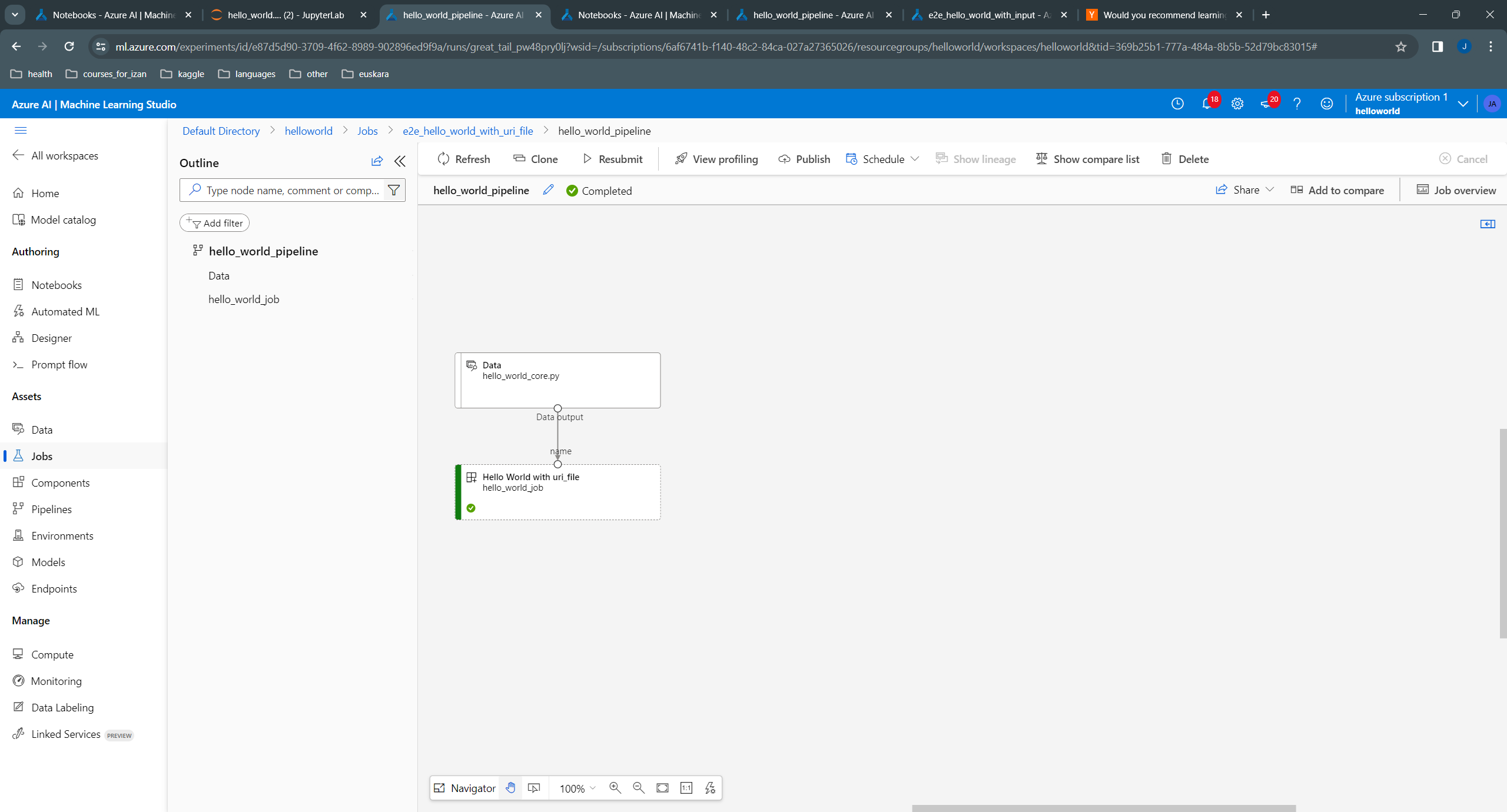
# Component definition and registration
job = command(
outputs=dict(
name=Output (type="uri_file"),
),
code=f"./", # location of source code: in this case, the root folder
command="python hello_world_core.py --name ${{outputs.name}}",
environment="AzureML-sklearn-1.0-ubuntu20.04-py38-cpu@latest",
display_name="Hello World with uri_file as output",
)
hello_world_component = ml_client.create_or_update(job.component)
# Pipeline definition and registration
@dsl.pipeline(
compute="serverless", # "serverless" value runs pipeline on serverless compute
description="E2E hello world pipeline with input",
)
def hello_world_pipeline(
):
# using data_prep_function like a python call with its own inputs
hello_world_job = hello_world_component()
pipeline = hello_world_pipeline()
pipeline_job = ml_client.jobs.create_or_update(
pipeline,
# Project's name
experiment_name="e2e_hello_world_with_uri_file_as_output",
)
# Pipeline running
ml_client.jobs.stream(pipeline_job.name)Uploading hello_world (9.48 MBs): 100%|██████████| 9483085/9483085 [00:00<00:00, 22969826.09it/s]
RunId: teal_soccer_m9bkcgz2gq
Web View: https://ml.azure.com/runs/teal_soccer_m9bkcgz2gq?wsid=/subscriptions/6af6741b-f140-48c2-84ca-027a27365026/resourcegroups/helloworld/workspaces/helloworld
Streaming logs/azureml/executionlogs.txt
========================================
[2024-03-26 15:36:23Z] Submitting 1 runs, first five are: 528b20ac:27e32a0a-71a0-4bc3-abec-eaeae70ff08e
[2024-03-26 15:41:30Z] Completing processing run id 27e32a0a-71a0-4bc3-abec-eaeae70ff08e.
Execution Summary
=================
RunId: teal_soccer_m9bkcgz2gq
Web View: https://ml.azure.com/runs/teal_soccer_m9bkcgz2gq?wsid=/subscriptions/6af6741b-f140-48c2-84ca-027a27365026/resourcegroups/helloworld/workspaces/helloworld
In order to have something more meaningful, we create a pipeline with two components. The first one “pre-processes” the input data frame by adding one (or a specified number) to it, storing the output as a csv file. The second component builds a “model” by calculating the mean and standard deviation, and saves it as pickle file.
Whenever we have multiple components, a common practice in Azure ML is to have a dedicated subfolder for each one. The subfolder contains the source .py file implementing the component, and may contain a conda yaml file with dependencies that are specific for this component. In our case, we use a pre-built environment so that we don’t need to include any conda yaml file.
os.makedirs ("preprocessing", exist_ok=True)
os.makedirs ("training", exist_ok=True)
os.makedirs ("data", exist_ok=True)df = pd.DataFrame (
{
"a": [1,2,3],
"b": [4,5,6],
},
)
df.to_csv ("data/dummy_input.csv")%%writefile preprocessing/preprocessing.py
import argparse
import pandas as pd
def preprocessing (df, x):
"""Adds `x` to input data frame `df`."""
print ("Input\n", df)
print (f"Adding {x} to df")
df = df + x
print ("Output\n", df)
return df
def parse_args ():
"""Parses input arguments"""
parser = argparse.ArgumentParser()
parser.add_argument("--input_data", type=str, help="path to input data frame")
parser.add_argument("--preprocessed_data", type=str, help="path to output data frame")
parser.add_argument("-x", type=int, help="number to add")
args = parser.parse_args()
return args
def read_and_preprocess (
input_data,
x,
preprocessed_data,
):
df = pd.read_csv (input_data, index_col=0)
df = preprocessing (df, x)
df.to_csv (preprocessed_data)
def main():
"""Main function of the script."""
args = parse_args ()
read_and_preprocess (args.input_data, args.x, args.preprocessed_data)
if __name__ == "__main__":
main()Overwriting preprocessing/preprocessing.py# Component definition and registration
preprocessing_command = command(
inputs=dict(
input_data=Input (type="uri_file"),
x=Input (type="number"),
),
outputs=dict(
preprocessed_data=Output (type="uri_file"),
),
code=f"./preprocessing/", # location of source code: in this case, the root folder
command="python preprocessing.py --input_data ${{inputs.input_data}} -x ${{inputs.x}} --preprocessed_data ${{outputs.preprocessed_data}}",
environment="AzureML-sklearn-1.0-ubuntu20.04-py38-cpu@latest",
display_name="Pre-processing",
)
preprocessing_component = ml_client.create_or_update(preprocessing_command.component)%%writefile training/training.py
import argparse
import joblib
import pandas as pd
def train_model (df: pd.DataFrame):
"""Trains a dummy Gaussian model from training set df."""
print ("Input\n", df)
mu = df.mean().values
std = df.std().values
print ("mu:\n", mu)
print ("std:\n", std)
return mu, std
def parse_args ():
"""Parses input arguments"""
parser = argparse.ArgumentParser()
parser.add_argument("--preprocessed_data", type=str, help="path to preprocessed data")
parser.add_argument("--model", type=str, help="path to built model")
args = parser.parse_args()
return args
def read_and_train (
preprocessed_data: str,
model_path: str,
):
"""Reads training data, trains model, and saves it."""
df = pd.read_csv (preprocessed_data, index_col=0)
model = train_model (df)
joblib.dump (model, model_path)
def main():
"""Main function of the script."""
args = parse_args ()
read_and_train (args.preprocessed_data, args.model)
if __name__ == "__main__":
main()Overwriting training/training.py# Component definition and registration
training_command = command(
inputs=dict(
preprocessed_data=Input (type="uri_file"),
),
outputs=dict(
model=Output (type="uri_file"),
),
code=f"./training/", # location of source code: in this case, the root folder
command="python training.py --preprocessed_data ${{inputs.preprocessed_data}} --model ${{outputs.model}}",
environment="AzureML-sklearn-1.0-ubuntu20.04-py38-cpu@latest",
display_name="Training",
)
training_component = ml_client.create_or_update(training_command.component)Uploading training (0.0 MBs): 100%|██████████| 1043/1043 [00:00<00:00, 112778.01it/s]
Before submitting the pipeline job, it is very important to test it first, ideally with some dummy or small dataset. For this purpose, in the component implementation above, we have separated the code related with argument parsing and the rest of the code, which is in encapsulated in a function called read_and_<...>. This way, we can easily write a test pipeline before implementing the final one, as follows:
# We will need to change the code as we iteratively refine it
# while testing the pipeline. For that purpose, we use the
# reload module
from importlib import reload
from preprocessing import preprocessing
from training import training
reload (preprocessing)
reload (training)
def test_pipeline (
pipeline_job_data_input: str,
pipeline_job_x: int,
pipeline_job_preprocess_output: str,
pipeline_job_model_output: str,
):
"""
Tests two component pipeline with preprocessing and training.
Parameters
----------
pipeline_job_data_input: str
Path to input data *file*
pipeline_job_x: int
Integer to add to input data to convert it to "preprocessed" data.
pipeline_job_test_input: str
Path to (preprocessed) test input *file*
pipeline_job_preprocess_output: str
Path to preprocessed data *file*, to be used as training.
Not present in the final pipeline.
pipeline_job_model_output: str
Path to model *file*. Not present in the final pipeline.
"""
preprocessing.read_and_preprocess (
pipeline_job_data_input,
pipeline_job_x,
pipeline_job_preprocess_output,
)
training.read_and_train (
pipeline_job_preprocess_output,
pipeline_job_model_output,
)
os.makedirs ("test_pipeline", exist_ok=True)
test_pipeline (
pipeline_job_data_input="./data/dummy_input.csv",
pipeline_job_x=10,
pipeline_job_preprocess_output="./test_pipeline/preprocessed_data.csv",
pipeline_job_model_output="./test_pipeline/model.pk"
)Input
a b
0 1 4
1 2 5
2 3 6
Adding 10 to df
Output
a b
0 11 14
1 12 15
2 13 16
Input
a b
0 11 14
1 12 15
2 13 16
mu:
[12. 15.]
std:
[1. 1.]Now we are ready to implement and submit our pipeline. The code will be very similar to the test_pipeline implemented above, except for the fact that we don’t need to indicate the outputs that connect one component to the next, since these are automatically populated by AML.
# Pipeline definition and registration
@dsl.pipeline(
compute="serverless", # "serverless" value runs pipeline on serverless compute
description="E2E hello world pipeline with input",
)
def two_components_pipeline(
pipeline_job_data_input: str,
pipeline_job_x: int,
):
"""
Pipeline with two components: preprocessing, and training.
Parameters
----------
pipeline_job_data_input: str
Path to input data *file*
pipeline_job_x: int
Integer to add to input data to convert it to "preprocessed" data.
"""
# using data_prep_function like a python call with its own inputs
preprocessing_job = preprocessing_component(
input_data=pipeline_job_data_input,
x=pipeline_job_x,
)
# using train_func like a python call with its own inputs
training_job = training_component(
preprocessed_data=preprocessing_job.outputs.preprocessed_data, # note: using outputs from previous step
)
two_components_pipeline = two_components_pipeline(
pipeline_job_data_input=Input(type="uri_file", path="./data/dummy_input.csv"),
pipeline_job_x=10,
)
two_components_pipeline_job = ml_client.jobs.create_or_update(
two_components_pipeline,
# Project's name
experiment_name="e2e_two_components_pipeline",
)
# Pipeline running
ml_client.jobs.stream(two_components_pipeline_job.name)RunId: quiet_root_nb0c997gsp
Web View: https://ml.azure.com/runs/quiet_root_nb0c997gsp?wsid=/subscriptions/6af6741b-f140-48c2-84ca-027a27365026/resourcegroups/helloworld/workspaces/helloworld
Streaming logs/azureml/executionlogs.txt
========================================
[2024-03-27 10:45:01Z] Submitting 1 runs, first five are: caf1c51e:87b5910c-0e8d-4ca0-a808-f52a94d52b56
[2024-03-27 10:51:05Z] Completing processing run id 87b5910c-0e8d-4ca0-a808-f52a94d52b56.
[2024-03-27 10:51:05Z] Submitting 1 runs, first five are: 3d73a420:6c033636-f3d8-4fe2-ba8d-26072210ba05
[2024-03-27 10:56:25Z] Completing processing run id 6c033636-f3d8-4fe2-ba8d-26072210ba05.
Execution Summary
=================
RunId: quiet_root_nb0c997gsp
Web View: https://ml.azure.com/runs/quiet_root_nb0c997gsp?wsid=/subscriptions/6af6741b-f140-48c2-84ca-027a27365026/resourcegroups/helloworld/workspaces/helloworld
We can see the created pipeline in the Pipelines section of our workspace:
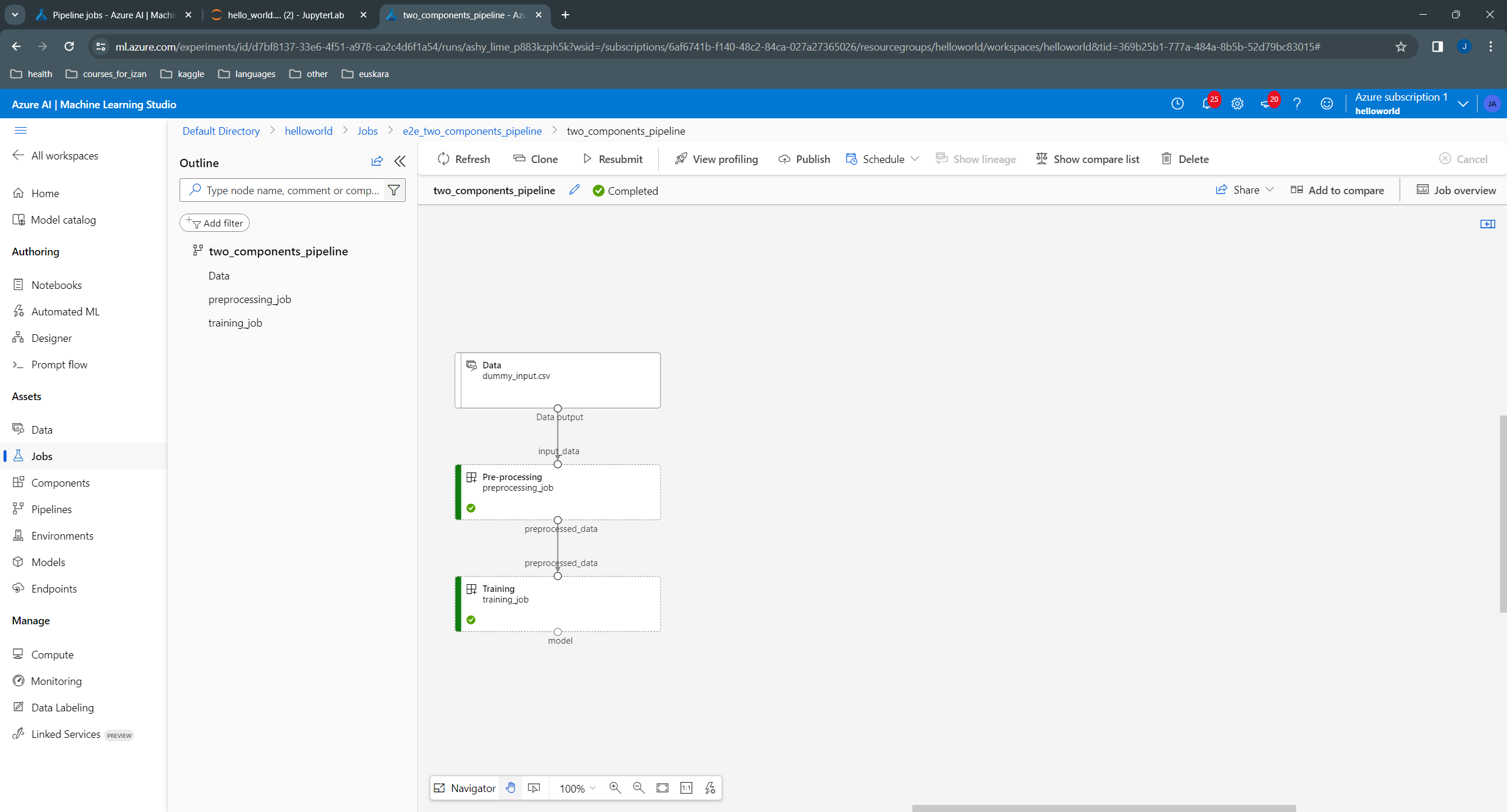
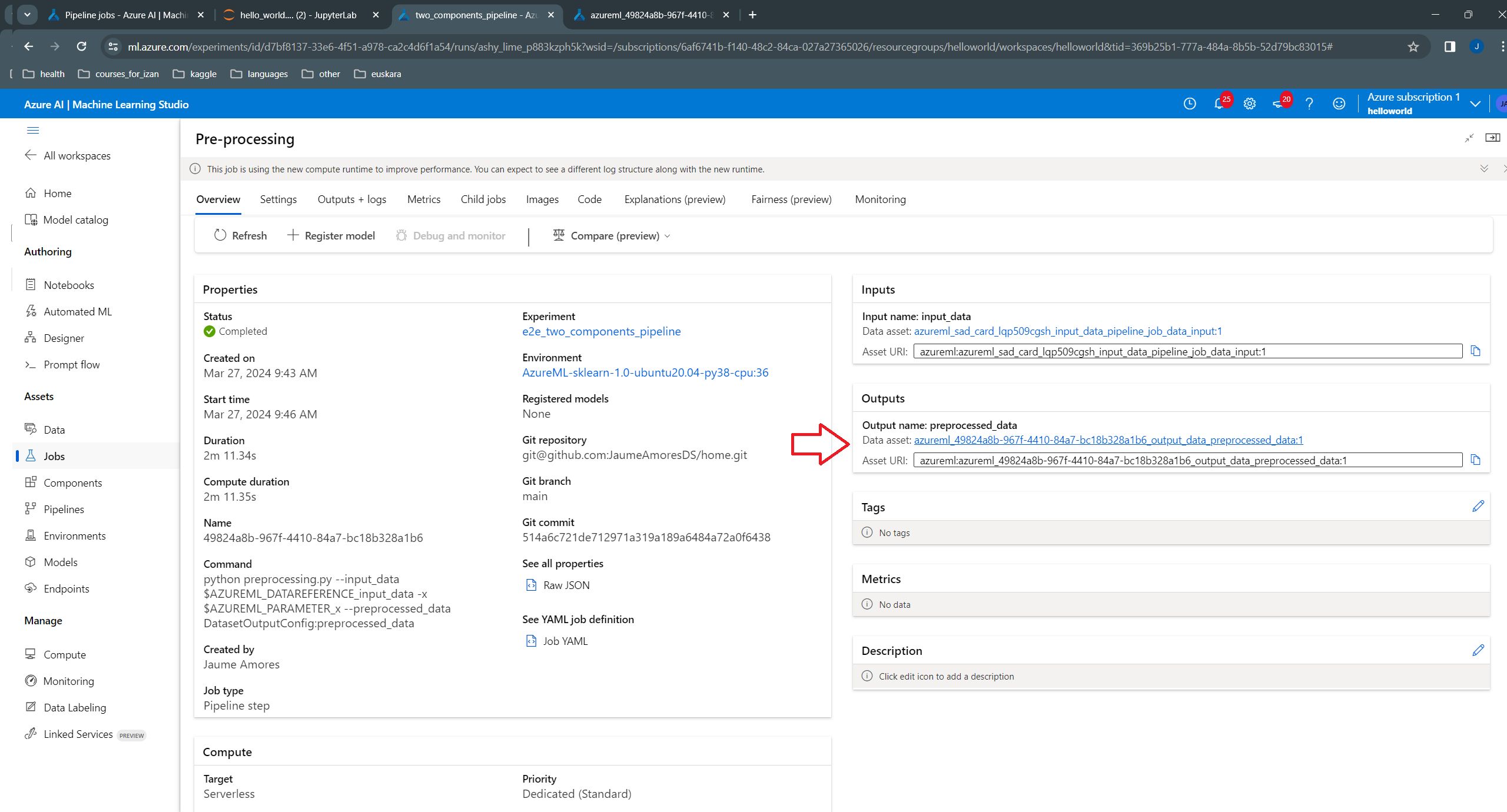
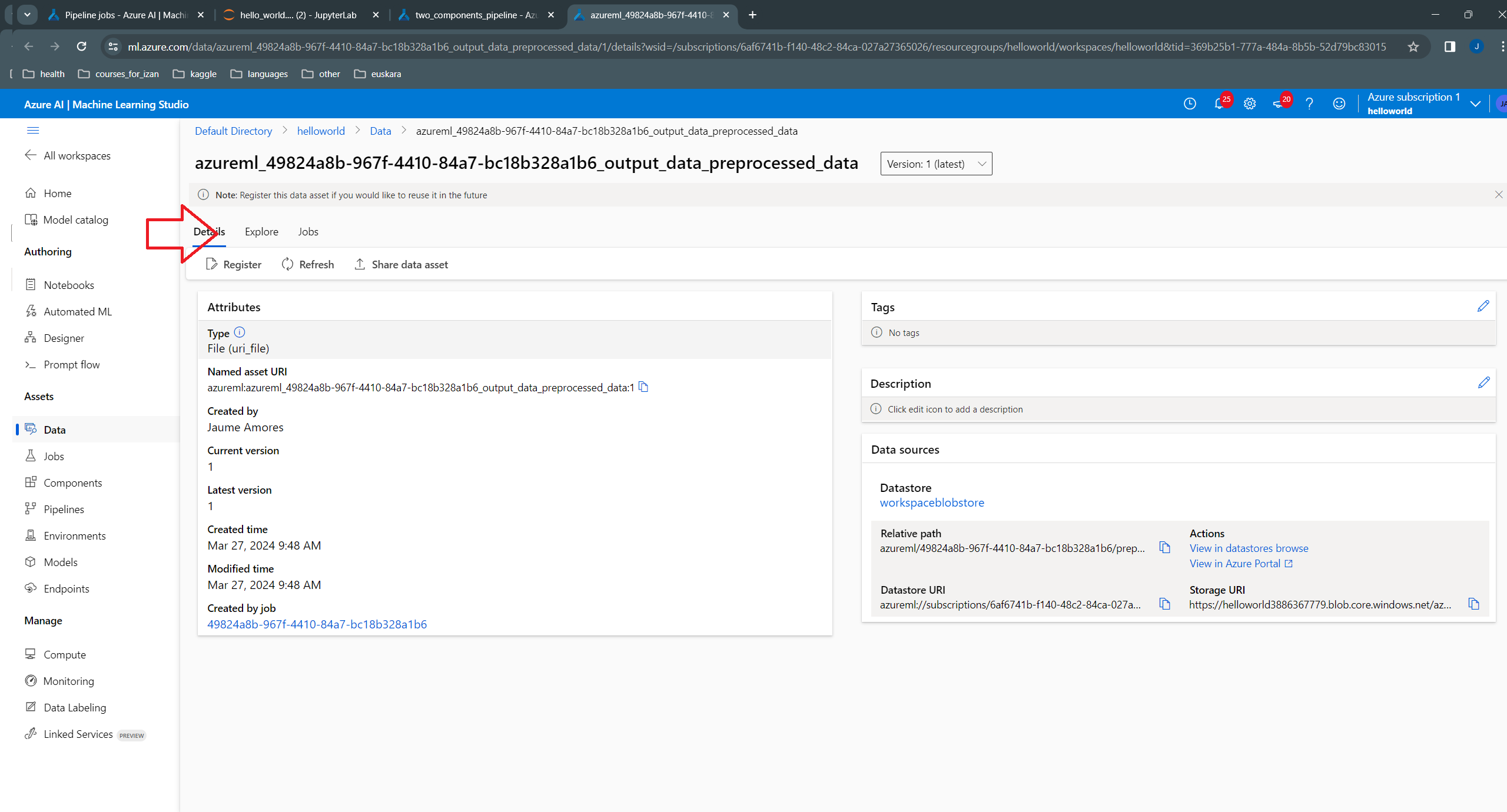
We can see that:
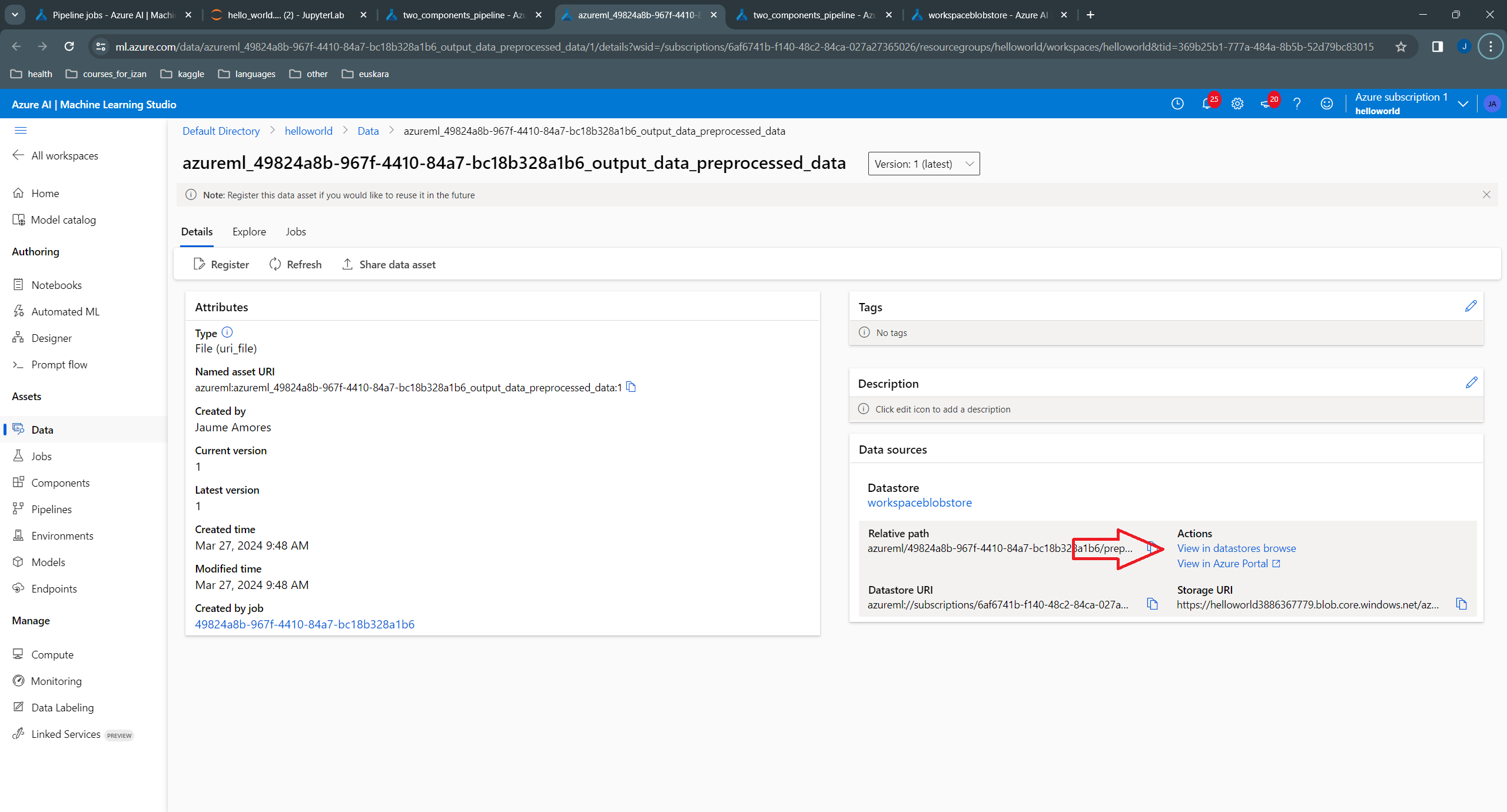
azureml/49824a8b-967f-4410-84a7-bc18b328a1b6/preprocessed_data, where the file name preprocessed_data is the name of the output given in the component definition: outputs=dict(
preprocessed_data=Output (type="uri_file"),
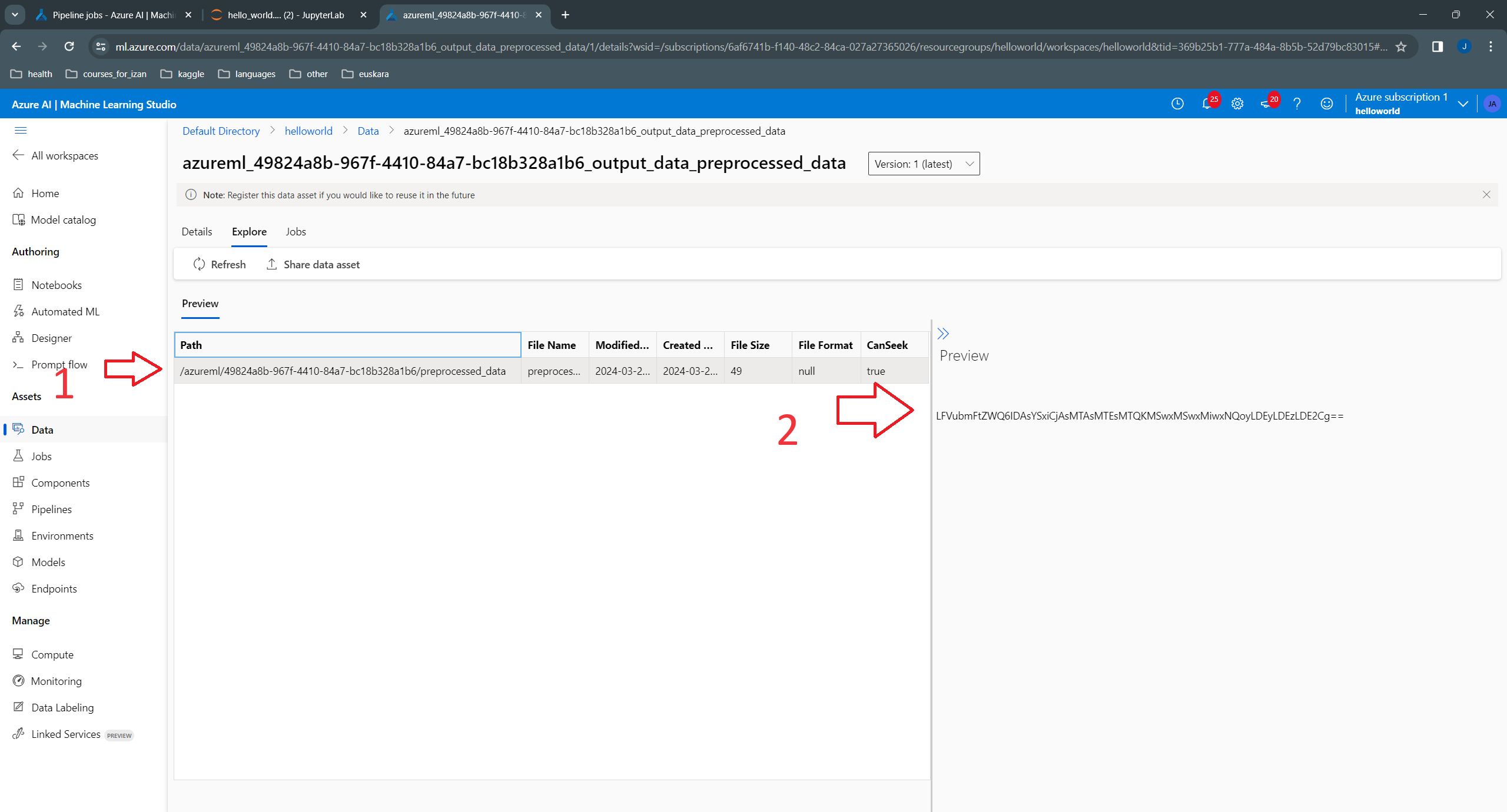
)
Unfortunately, the content of the file appears in text format, rather than as a table.
We can also see the content of the outputs by inspecting the logs of the training component:
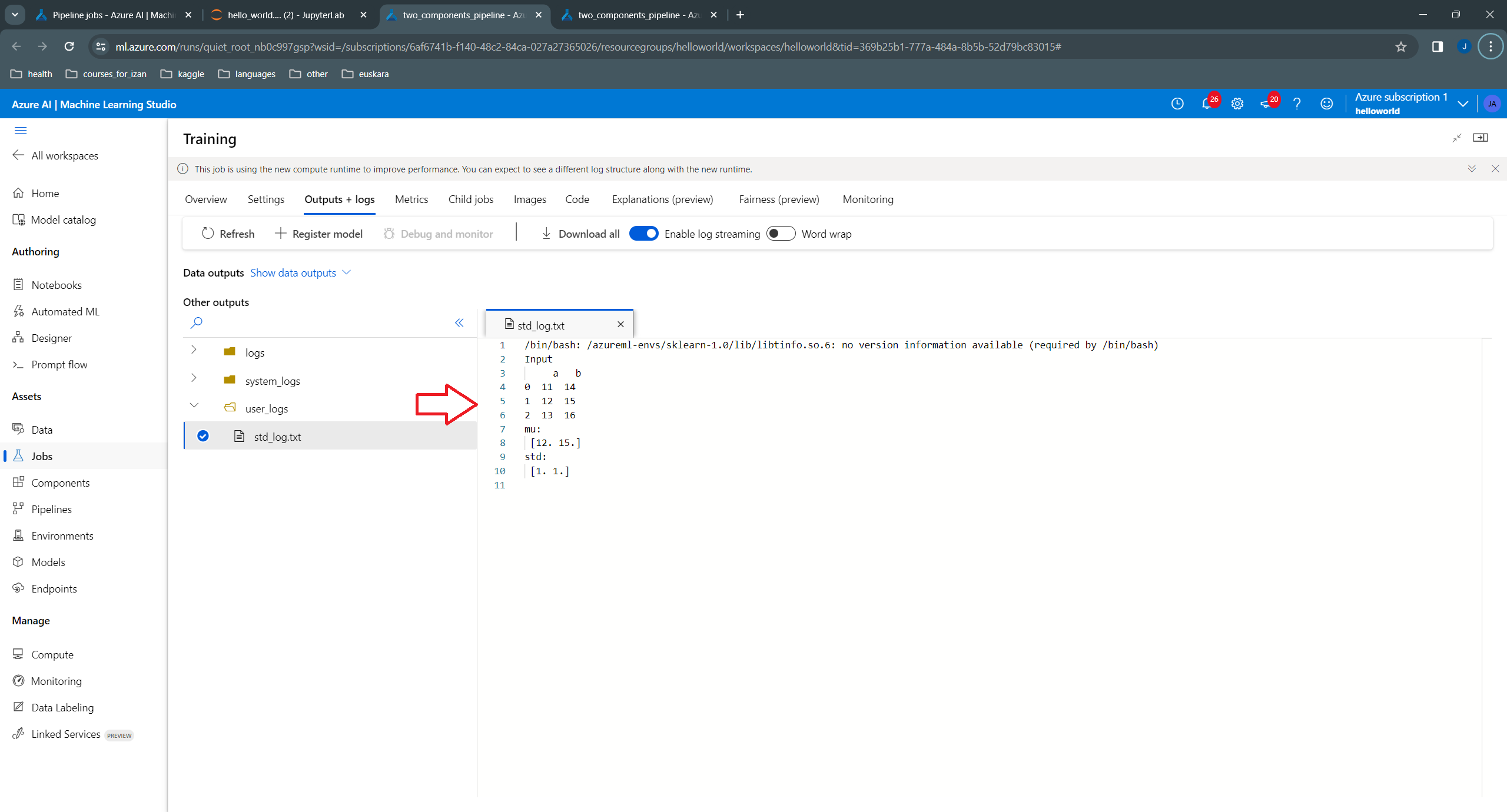
Let’s try now using outputs of type “uri_folder”. We need to do two changes for this purpose:
args.preprocessed_data and args.model will contain a path to a folder where the file is stored. Therefore, when saving the file, we need to append its name to the input path:#In preprocessing module:
df.to_csv (preprocessed_data + "/preprocessed_data.csv")and
# In training module:
df = pd.read_csv (preprocessed_data + "/preprocessed_data.csv", index_col=0)
# later in same module:
joblib.dump (model, model_path + "/model.pk") # In preprocessing component
...
outputs=dict(
preprocessed_data=Output (type="uri_folder"),
),
...
# In training component
...
inputs=dict(
preprocessed_data=Input (type="uri_folder"),
),
outputs=dict(
model=Output (type="uri_folder"),
),
...Here we have the final implementation of our components:
%%writefile preprocessing/preprocessing.py
import argparse
import pandas as pd
def preprocessing (df, x):
"""Adds `x` to input data frame `df`."""
print ("Input\n", df)
print (f"Adding {x} to df")
df = df + x
print ("Output\n", df)
return df
def parse_args ():
"""Parses input arguments"""
parser = argparse.ArgumentParser()
parser.add_argument("--input_data", type=str, help="path to input data *file*")
parser.add_argument("--preprocessed_data", type=str, help="path to output data *folder* containing the preprocessed data.")
parser.add_argument("-x", type=int, help="number to add")
args = parser.parse_args()
return args
def read_and_preprocess (
input_data,
x,
preprocessed_data,
):
df = pd.read_csv (input_data, index_col=0)
df = preprocessing (df, x)
df.to_csv (preprocessed_data + "/preprocessed_data.csv")
def main():
"""Main function of the script."""
args = parse_args ()
read_and_preprocess (args.input_data, args.x, args.preprocessed_data)
if __name__ == "__main__":
main()Overwriting preprocessing/preprocessing.pypreprocessing_command = command(
inputs=dict(
input_data=Input (type="uri_file"),
x=Input (type="number"),
),
outputs=dict(
preprocessed_data=Output (type="uri_folder"),
),
code=f"./preprocessing/", # location of source code: in this case, the root folder
command="python preprocessing.py --input_data ${{inputs.input_data}} -x ${{inputs.x}} --preprocessed_data ${{outputs.preprocessed_data}}",
environment="AzureML-sklearn-1.0-ubuntu20.04-py38-cpu@latest",
display_name="Pre-processing",
)
preprocessing_component = ml_client.create_or_update(preprocessing_command.component)%%writefile training/training.py
import argparse
import joblib
import pandas as pd
def train_model (df: pd.DataFrame):
"""Trains a dummy Gaussian model from training set df."""
print ("Input\n", df)
mu = df.mean().values
std = df.std().values
print ("mu:\n", mu)
print ("std:\n", std)
return mu, std
def parse_args ():
"""Parses input arguments"""
parser = argparse.ArgumentParser()
parser.add_argument("--preprocessed_data", type=str, help="path to preprocessed data")
parser.add_argument("--model", type=str, help="path to built model")
args = parser.parse_args()
return args
def read_and_train (
preprocessed_data: str,
model_path: str,
):
"""Reads training data, trains model, and saves it."""
df = pd.read_csv (preprocessed_data + "/preprocessed_data.csv", index_col=0)
model = train_model (df)
joblib.dump (model, model_path + "/model.pk")
def main():
"""Main function of the script."""
args = parse_args ()
read_and_train (args.preprocessed_data, args.model)
if __name__ == "__main__":
main()Overwriting training/training.py# Component definition and registration
training_command = command(
inputs=dict(
preprocessed_data=Input (type="uri_folder"),
),
outputs=dict(
model=Output (type="uri_folder"),
),
code=f"./training/", # location of source code: in this case, the root folder
command="python training.py --preprocessed_data ${{inputs.preprocessed_data}} --model ${{outputs.model}}",
environment="AzureML-sklearn-1.0-ubuntu20.04-py38-cpu@latest",
display_name="Training",
)
training_component = ml_client.create_or_update(training_command.component)Uploading training (0.0 MBs): 100%|██████████| 1084/1084 [00:00<00:00, 39997.06it/s]
Again, before submitting the pipeline job, we first test a manually built pipeline. Note that the new pipeline uses paths to folders, and not paths to files, for the outputs:
from importlib import reload
from preprocessing import preprocessing
from training import training
reload (preprocessing)
reload (training)
def test_pipeline (
pipeline_job_data_input: str,
pipeline_job_x: int,
pipeline_job_preprocess_output: str,
pipeline_job_model_output: str,
):
"""
Tests two component pipeline with preprocessing and training.
Parameters
----------
pipeline_job_data_input: str
Path to input data *file*
pipeline_job_x: int
Integer to add to input data to convert it to "preprocessed" data.
pipeline_job_test_input: str
Path to (preprocessed) test input *file*
pipeline_job_preprocess_output: str
Path to preprocessed data *folder*, to be used as training.
Not present in the final pipeline.
pipeline_job_model_output: str
Path to model *folder*. Not present in the final pipeline.
"""
preprocessing.read_and_preprocess (
pipeline_job_data_input,
pipeline_job_x,
pipeline_job_preprocess_output,
)
training.read_and_train (
pipeline_job_preprocess_output,
pipeline_job_model_output,
)
os.makedirs ("test_pipeline", exist_ok=True)
test_pipeline (
pipeline_job_data_input="./data/dummy_input.csv",
pipeline_job_x=10,
pipeline_job_preprocess_output="./test_pipeline",
pipeline_job_model_output="./test_pipeline"
)Input
a b
0 1 4
1 2 5
2 3 6
Adding 10 to df
Output
a b
0 11 14
1 12 15
2 13 16
Input
a b
0 11 14
1 12 15
2 13 16
mu:
[12. 15.]
std:
[1. 1.]… and the implementation of our pipeline:
@dsl.pipeline(
compute="serverless", # "serverless" value runs pipeline on serverless compute
description="E2E hello world pipeline with input",
)
def two_components_pipeline(
pipeline_job_data_input,
pipeline_job_x,
):
"""
Pipeline with two components: preprocessing, and training.
Parameters
----------
pipeline_job_data_input: str
Path to input data *file*
pipeline_job_x: int
Integer to add to input data to convert it to "preprocessed" data.
"""
# using data_prep_function like a python call with its own inputs
preprocessing_job = preprocessing_component(
input_data=pipeline_job_data_input,
x=pipeline_job_x,
)
# using train_func like a python call with its own inputs
training_job = training_component(
preprocessed_data=preprocessing_job.outputs.preprocessed_data, # note: using outputs from previous step
)
two_components_pipeline = two_components_pipeline(
pipeline_job_data_input=Input(type="uri_file", path="./data/dummy_input.csv"),
pipeline_job_x=10,
)
two_components_pipeline_job = ml_client.jobs.create_or_update(
two_components_pipeline,
# Project's name
experiment_name="e2e_two_components_pipeline_with_uri_folder",
)
# ----------------------------------------------------
# Pipeline running
# ----------------------------------------------------
ml_client.jobs.stream(two_components_pipeline_job.name)RunId: calm_zebra_t3gb5cjnrk
Web View: https://ml.azure.com/runs/calm_zebra_t3gb5cjnrk?wsid=/subscriptions/6af6741b-f140-48c2-84ca-027a27365026/resourcegroups/helloworld/workspaces/helloworld
Streaming logs/azureml/executionlogs.txt
========================================
[2024-03-28 08:45:53Z] Completing processing run id 1ff53a74-943f-4f94-8efd-4b55b345449f.
[2024-03-28 08:45:54Z] Submitting 1 runs, first five are: e26d0be6:8e0f40eb-e2c3-4feb-a0d0-9882de1daebc
Execution Summary
=================
RunId: calm_zebra_t3gb5cjnrk
Web View: https://ml.azure.com/runs/calm_zebra_t3gb5cjnrk?wsid=/subscriptions/6af6741b-f140-48c2-84ca-027a27365026/resourcegroups/helloworld/workspaces/helloworld
Now, when we go to the “Explore” tab, in the output data of the preprocessed component, we can see the contents of the output preprocessed data in tabular format. We can also see that the extension of the output, which is csv file:
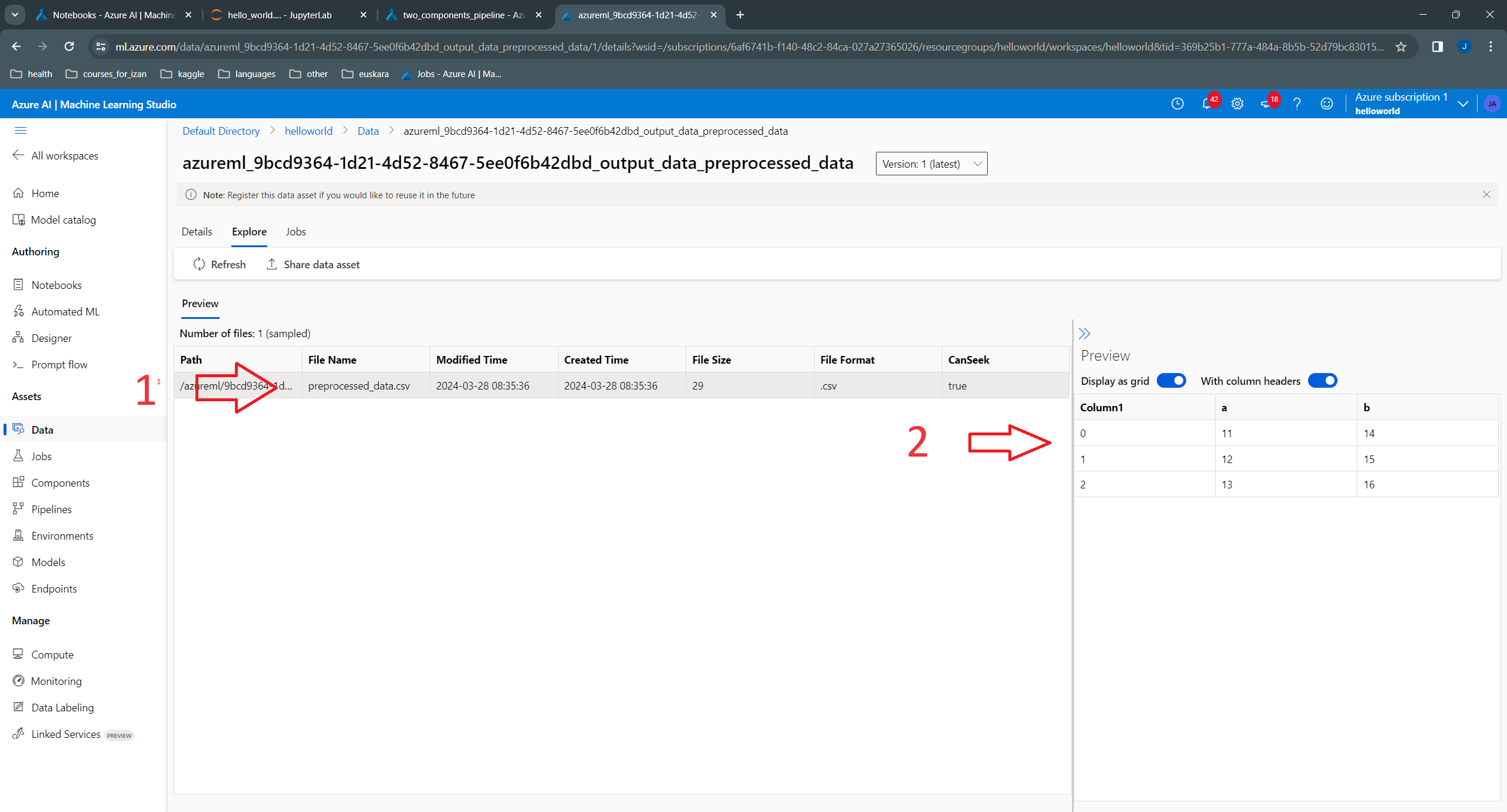
We add now a third component, which takes as input test data, preprocesses it, and uses the model to perform “inference”. For this pipeline, we can reuse the training component from the last section, but we need to slighty modify the preprocessing component to use an additional argument: the name of the output file. This is needed because there will be two outputs: one when preprocessing the training data, and the other when preprocessing the test data.
os.makedirs ("inference", exist_ok=True)
test_data = pd.DataFrame (
{
"a": [11., 12.1, 13.1],
"b": [14.1, 15.1, 16.1],
}
)
test_data.to_csv ("data/dummy_test.csv")%%writefile preprocessing/preprocessing.py
import argparse
import pandas as pd
def preprocessing (df, x):
"""Adds `x` to input data frame `df`."""
print ("Input\n", df)
print (f"Adding {x} to df")
df = df + x
print ("Output\n", df)
return df
def parse_args ():
"""Parses input arguments"""
parser = argparse.ArgumentParser()
parser.add_argument("--input_data", type=str, help="path to input data *file*")
parser.add_argument("--preprocessed_data", type=str, help="path to output data *folder* containing the preprocessed data.")
parser.add_argument("--preprocessed_file_name", type=str, help="name of preprocessed file name.")
parser.add_argument("-x", type=int, help="number to add")
args = parser.parse_args()
return args
def read_and_preprocess (
input_data: str,
preprocessed_data: str,
preprocessed_file_name: str,
x: int,
):
df = pd.read_csv (input_data, index_col=0)
df = preprocessing (df, x)
df.to_csv (f"{preprocessed_data}/{preprocessed_file_name}")
def main():
"""Main function of the script."""
args = parse_args ()
read_and_preprocess (
input_data=args.input_data,
preprocessed_data=args.preprocessed_data,
preprocessed_file_name=args.preprocessed_file_name,
x=args.x,
)
if __name__ == "__main__":
main()Overwriting preprocessing/preprocessing.pypreprocessing_command = command(
inputs=dict(
input_data=Input (type="uri_file"),
x=Input (type="number"),
preprocessed_file_name=Input (type="string"),
),
outputs=dict(
preprocessed_data=Output (type="uri_folder"),
),
code=f"./preprocessing/", # location of source code: in this case, the root folder
command="python preprocessing.py --input_data ${{inputs.input_data}} -x ${{inputs.x}} --preprocessed_data ${{outputs.preprocessed_data}} --preprocessed_file_name ${{inputs.preprocessed_file_name}}",
environment="AzureML-sklearn-1.0-ubuntu20.04-py38-cpu@latest",
display_name="Pre-processing",
)
preprocessing_component = ml_client.create_or_update(preprocessing_command.component)Uploading preprocessing (0.0 MBs): 100%|██████████| 1343/1343 [00:00<00:00, 46879.53it/s]
The preprocessing component doesn’t change from the last pipeline, see “Using uri_folder” section.
%%writefile inference/inference.py
import argparse
import joblib
import pandas as pd
from typing import Tuple
import numpy as np
def inference (
model: Tuple[np.ndarray, np.ndarray],
df: pd.DataFrame,
):
"""
Runs dummy inference on new data `df`
"""
(mu, std) = model
z_df = (df - mu) / std
print ("Inference result:")
print (z_df)
return z_df
def parse_args ():
"""Parses input arguments"""
parser = argparse.ArgumentParser()
parser.add_argument("--test_data", type=str, help="path to test data *folder*")
parser.add_argument("--test_data_file_name", type=str, help="name of test data file name.")
parser.add_argument("--model", type=str, help="path to built model *folder*")
parser.add_argument("--inference_output", type=str, help="path to inference result *folder*")
args = parser.parse_args()
return args
def read_and_inference (
test_data: str,
test_data_file_name: str,
model_path: str,
inference_data: str,
):
"""
Reads test data and model, performs inference, and writes to output inference file.
Parameters
----------
test_data: str
Path to test (preprocessed) data *folder*
test_data_file_name: str
Name of test data file.
model_path: str
Path to built model *folder*
inference_data: str
Path to inference result *folder*
"""
df = pd.read_csv (f"{test_data}/{test_data_file_name}", index_col=0)
model = joblib.load (model_path + "/model.pk")
z_df = inference (model, df)
z_df.to_csv (inference_data + "/inference_result.csv")
def main():
"""Main function of the script."""
args = parse_args ()
read_and_inference (
test_data=args.test_data,
test_data_file_name=args.test_data_file_name,
model_path=args.model,
inference_data=args.inference_output,
)
if __name__ == "__main__":
main()Overwriting inference/inference.pyinference_command = command(
inputs=dict(
test_data=Input (type="uri_folder"),
test_data_file_name=Input (type="string"),
model=Input (type="uri_folder"),
),
outputs=dict(
inference_output=Output (type="uri_folder"),
),
code=f"./inference/", # location of source code: in this case, the root folder
command="python inference.py "
"--test_data ${{inputs.test_data}} "
"--test_data_file_name ${{inputs.test_data_file_name}} "
"--model ${{inputs.model}} "
"--inference_output ${{outputs.inference_output}}",
environment="AzureML-sklearn-1.0-ubuntu20.04-py38-cpu@latest",
display_name="inference",
)
inference_component = ml_client.create_or_update(inference_command.component)Uploading inference (0.0 MBs): 100%|██████████| 1912/1912 [00:00<00:00, 63810.98it/s]
Before submitting the pipeline job, it is very important to test it first, ideally with some dummy or small dataset. For this purpose, in the component implementation above, we have separated the code related with argument parsing and the rest of the code, which is in encapsulated in a function called read_and_<...>. This way, we can easily write a test pipeline before implementing the final one, as follows:
# We will need to change the code as we iteratively refine it
# while testing the pipeline. For that purpose, we use the
# reload module
from importlib import reload
from preprocessing import preprocessing
from training import training
from inference import inference
reload (preprocessing)
reload (training)
reload (inference)
def test_pipeline (
pipeline_job_data_input: str,
pipeline_job_x: int,
pipeline_job_test_input: str,
pipeline_preprocessed_file_name: str,
pipeline_test_file_name: str,
# The following parameters are not present in the final pipeline:
pipeline_job_preprocess_output: str,
pipeline_job_test_output: str,
pipeline_job_model_output: str,
pipeline_job_inference_output: str,
):
"""
Tests third pipeline: preprocessing, training and inference.
Parameters
----------
pipeline_job_data_input: str
Path to input data *file*
pipeline_job_x: int
Integer to add to input data to convert it to "preprocessed" data.
pipeline_job_test_input: str
Path to (preprocessed) test input *file*
pipeline_job_test_input: str
Path to (preprocessed) test input *file*
pipeline_preprocessed_file_name: str
Name of (preprocessed) input data file.
pipeline_test_file_name: str
Name of (preprocessed) test data file.
pipeline_job_preprocess_output: str
Path to preprocessed data *folder*, to be used as training.
Not present in the final pipeline.
pipeline_job_test_output: str
Path to preprocessed test data *folder*, to be used for inferencing.
Not present in the final pipeline.
pipeline_job_model_output: str
Path to model *folder*. Not present in the final pipeline.
pipeline_job_inference_output: str
Path to inference result *folder*. Not present in the final pipeline.
"""
preprocessing.read_and_preprocess (
pipeline_job_data_input,
pipeline_job_preprocess_output,
pipeline_preprocessed_file_name,
pipeline_job_x,
)
preprocessing.read_and_preprocess (
pipeline_job_test_input,
pipeline_job_test_output,
pipeline_test_file_name,
pipeline_job_x,
)
training.read_and_train (
pipeline_job_preprocess_output,
pipeline_job_model_output,
)
inference.read_and_inference (
test_data=pipeline_job_test_output,
test_data_file_name=pipeline_test_file_name,
model_path=pipeline_job_model_output,
inference_data=pipeline_job_inference_output,
)
os.makedirs ("test_pipeline", exist_ok=True)
test_pipeline (
pipeline_job_data_input="./data/dummy_input.csv",
pipeline_job_x=10,
pipeline_job_test_input="./data/dummy_test.csv",
pipeline_preprocessed_file_name="preprocessed_data.csv",
pipeline_test_file_name="preprocessed_test.csv",
# The following parameters are not present in the final pipeline:
pipeline_job_preprocess_output="./test_pipeline",
pipeline_job_test_output="./test_pipeline",
pipeline_job_model_output="./test_pipeline",
pipeline_job_inference_output="./test_pipeline",
)Input
a b
0 1 4
1 2 5
2 3 6
Adding 10 to df
Output
a b
0 11 14
1 12 15
2 13 16
Input
a b
0 11.0 14.1
1 12.1 15.1
2 13.1 16.1
Adding 10 to df
Output
a b
0 21.0 24.1
1 22.1 25.1
2 23.1 26.1
Input
a b
0 11 14
1 12 15
2 13 16
mu:
[12. 15.]
std:
[1. 1.]
Inference result:
a b
0 9.0 9.1
1 10.1 10.1
2 11.1 11.1@dsl.pipeline(
compute="serverless", # "serverless" value runs pipeline on serverless compute
description="E2E hello world pipeline with input",
)
def three_components_pipeline(
pipeline_job_data_input: str,
pipeline_job_x: int,
pipeline_job_test_input: str,
pipeline_preprocessed_file_name: str,
pipeline_test_file_name: str,
):
"""
Third pipeline: preprocessing, training and inference.
Parameters
----------
pipeline_job_data_input: str
Path to input data *file*
pipeline_job_x: int
Integer to add to input data to convert it to "preprocessed" data.
pipeline_job_test_input: str
Path to (preprocessed) test input *file*
pipeline_preprocessed_file_name: str
Name of (preprocessed) input data file.
pipeline_test_file_name: str
Name of (preprocessed) test data file.
"""
# using data_prep_function like a python call with its own inputs
preprocessing_job = preprocessing_component(
input_data=pipeline_job_data_input,
x=pipeline_job_x,
preprocessed_file_name=pipeline_preprocessed_file_name,
)
preprocessing_test_job = preprocessing_component(
input_data=pipeline_job_test_input,
x=pipeline_job_x,
preprocessed_file_name=pipeline_test_file_name,
)
# using train_func like a python call with its own inputs
training_job = training_component(
preprocessed_data=preprocessing_job.outputs.preprocessed_data, # note: using outputs from previous step
)
# using train_func like a python call with its own inputs
inference_job = inference_component(
test_data=preprocessing_test_job.outputs.preprocessed_data,
test_data_file_name=pipeline_test_file_name,
model=training_job.outputs.model, # note: using outputs from previous step
)
three_components_pipeline = three_components_pipeline(
pipeline_job_data_input=Input(type="uri_file", path="./data/dummy_input.csv"),
pipeline_job_x=10,
pipeline_job_test_input=Input(type="uri_file", path="./data/dummy_test.csv"),
pipeline_preprocessed_file_name="preprocessed_data.csv",
pipeline_test_file_name="preprocessed_test_data.csv",
)
three_components_pipeline_job = ml_client.jobs.create_or_update(
three_components_pipeline,
# Project's name
experiment_name="e2e_three_components_pipeline_with_uri_folder",
)
# ----------------------------------------------------
# Pipeline running
# ----------------------------------------------------
ml_client.jobs.stream(three_components_pipeline_job.name)RunId: calm_rice_3cmmmtc5mf
Web View: https://ml.azure.com/runs/calm_rice_3cmmmtc5mf?wsid=/subscriptions/6af6741b-f140-48c2-84ca-027a27365026/resourcegroups/helloworld/workspaces/helloworld
Streaming logs/azureml/executionlogs.txt
========================================
[2024-03-28 10:15:12Z] Submitting 2 runs, first five are: 47ca85c2:a5595dea-3117-47e9-a99d-186b0c346884,4b1f0180:09aecbcc-aa2c-4cad-b134-eb4837724f58
[2024-03-28 10:20:13Z] Completing processing run id 09aecbcc-aa2c-4cad-b134-eb4837724f58.
[2024-03-28 10:20:13Z] Submitting 1 runs, first five are: fece868d:164d1e2a-a5d7-4081-9a68-a07033a3feee
[2024-03-28 10:20:45Z] Completing processing run id 164d1e2a-a5d7-4081-9a68-a07033a3feee.
[2024-03-28 10:22:15Z] Completing processing run id a5595dea-3117-47e9-a99d-186b0c346884.
[2024-03-28 10:22:16Z] Submitting 1 runs, first five are: a9d60b27:6a18ae74-2a3c-4e16-a6cb-a58649235bfe
[2024-03-28 10:22:52Z] Completing processing run id 6a18ae74-2a3c-4e16-a6cb-a58649235bfe.
Execution Summary
=================
RunId: calm_rice_3cmmmtc5mf
Web View: https://ml.azure.com/runs/calm_rice_3cmmmtc5mf?wsid=/subscriptions/6af6741b-f140-48c2-84ca-027a27365026/resourcegroups/helloworld/workspaces/helloworld
Here we can see the resulting pipeline:
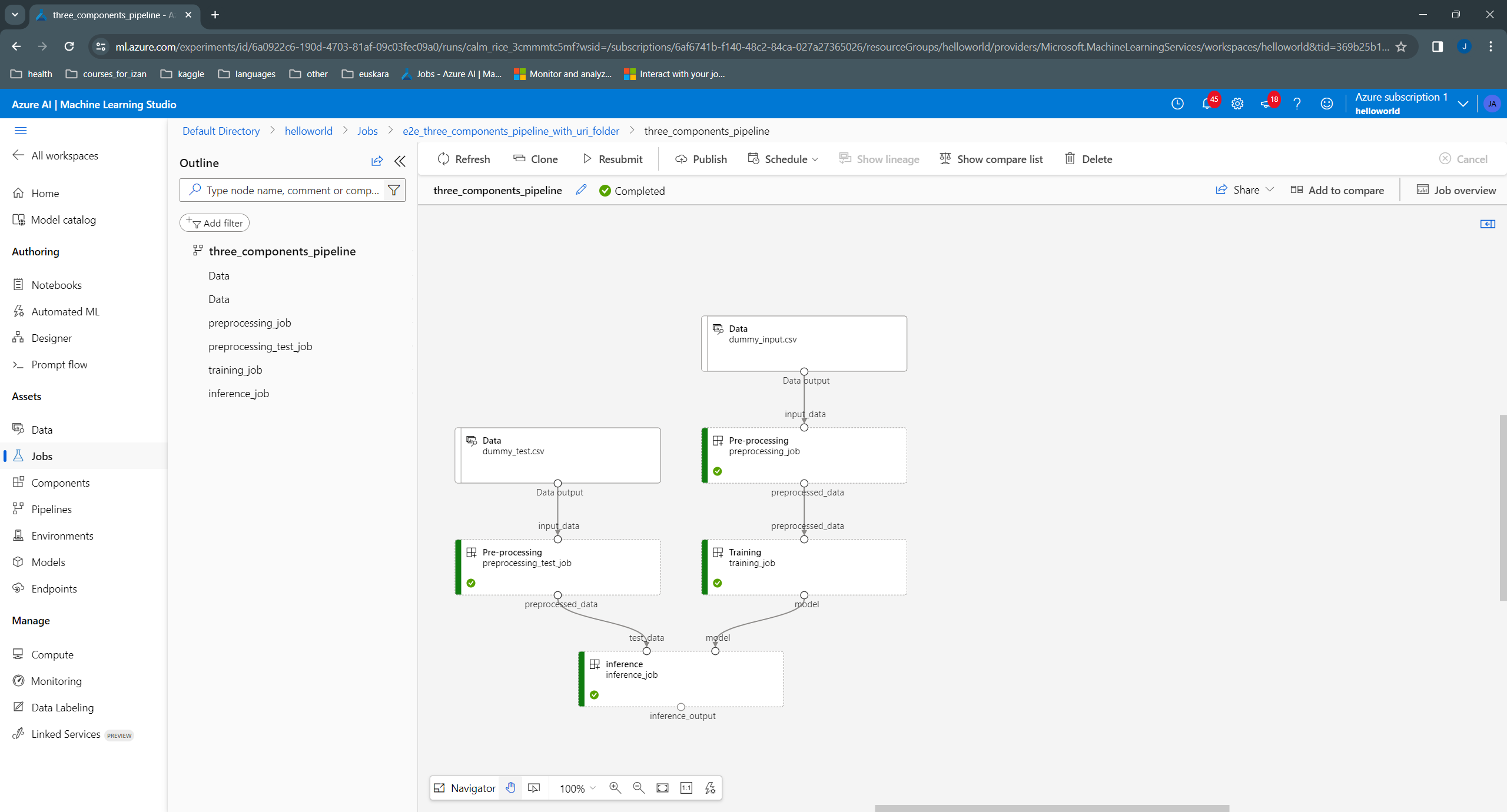
From the development of the different pipelines we can extract a few observations that help us create a better refactored pipeline and, at the same time, compile a small set of “design” rules that may help us in future pipelines. In my case, I find it clearer and with less boilerplate to use the following rules:
def pipeline(
...
input_folder: str,
input_filename: str,
...
)Use “_folder” as a prefix for parameters of type uri_folder, “_file” for those of type uri_file, and “_filename” for those indicating names of file names.
Use the suffix input for those things that are inputs and ouputfor those that are outputs.
I’m not clear about this one. Many people usually pass a dataframe called df or a numpy array called X, which is passed from one step of the pipeline to the next, without appending words to the name that talk about the content of the dataframe or the array (e.g., use “X” instead of “preprocessed_X” or “inference_result_X”). I tend to find it easier to do a similar thing here for the inputs of intermediate components, when defining the command for those components. Therefore, for the inputs, I would use input_folder rather than preprocessed_training_data_input_folder for indicating the input to the model component. This means that if we replace later the model component with one that works directly on raw (non-preprocessed) data (e.g., because the preprocessing is implicitly done as part of the model), we don’t need to replace the part of the script that parses the arguments to indicate that now the input folder is just training_data_input_folder.
For the outputs, it might be useful to add a short prefix to talk about the type of output, so that the pipeline’s diagram shows what is the ouput of each component is. Again, I’m not clear about this one.
The exception to the previous rules is when we have more than one input or output folder. In this case, we clearly need to add more words to their names.
It is easier to avoid adding pipeline_job_... for each parameter of the pipeline.
%%writefile preprocessing/preprocessing.py
import argparse
import pandas as pd
def preprocessing (
df: pd.DataFrame,
x: int
):
"""Adds `x` to input data frame `df`.
Parameters
----------
df: DataFrame
Input data frame
x: int
Integer to add to df.
Returns
-------
DataFrame.
Preprocessed data.
"""
print ("Input\n", df)
print (f"Adding {x} to df")
df = df + x
print ("Output\n", df)
return df
def parse_args ():
"""Parses input arguments"""
parser = argparse.ArgumentParser()
parser.add_argument("--input_file", type=str, help="path to input data file")
parser.add_argument("--output_folder", type=str, help="path to output data folder containing the preprocessed data.")
parser.add_argument("--output_filename", type=str, help="name of file containing the output, preprocessed, data.")
parser.add_argument("-x", type=int, help="number to add to input data for preprocessing it.")
args = parser.parse_args()
return args
def read_and_preprocess (
input_file: str,
output_folder: str,
output_filename: str,
x: int,
):
"""Reads input data, preprocesses it, and writes result as csv file in disk.
Parameters
----------
input_file: str
Path to input data file.
output_folder: str
Path to output data folder containing the preprocessed data.
output_filename: str
Name of file containing the output, preprocessed, data.
x: int
Number to add to input data for preprocessing it.
"""
df = pd.read_csv (input_file, index_col=0)
df = preprocessing (df, x)
df.to_csv (f"{output_folder}/{output_filename}")
def main():
"""Main function of the script."""
args = parse_args ()
read_and_preprocess (
input_file=args.input_file,
output_folder=args.output_folder,
output_filename=args.output_filename,
x=args.x,
)
if __name__ == "__main__":
main()Overwriting preprocessing/preprocessing.pypreprocessing_command = command(
inputs=dict(
input_file=Input (type="uri_file"),
x=Input (type="number"),
output_filename=Input (type="string"),
),
outputs=dict(
output_folder=Output (type="uri_folder"),
),
code=f"./preprocessing/", # location of source code: in this case, the root folder
command="python preprocessing.py "
"--input_file ${{inputs.input_file}} "
"-x ${{inputs.x}} "
"--output_folder ${{outputs.output_folder}} "
"--output_filename ${{inputs.output_filename}}",
environment="AzureML-sklearn-1.0-ubuntu20.04-py38-cpu@latest",
display_name="Pre-processing",
)
preprocessing_component = ml_client.create_or_update(preprocessing_command.component)Uploading preprocessing (0.0 MBs): 100%|██████████| 1985/1985 [00:00<00:00, 64070.90it/s]
%%writefile training/training.py
import argparse
import joblib
import pandas as pd
def train_model (df: pd.DataFrame):
"""Trains a dummy Gaussian model from training set df.
Parameters
----------
df: DataFrame
Input data frame
Returns
-------
np.ndarray
Average across rows, one per column.
np.ndarray
Standard deviation across rows, one per column.
"""
print ("Input\n", df)
mu = df.mean().values
std = df.std().values
print ("mu:\n", mu)
print ("std:\n", std)
return mu, std
def parse_args ():
"""Parses input arguments"""
parser = argparse.ArgumentParser()
parser.add_argument(
"--input_folder",
type=str,
help="path to preprocessed training data folder, "
"containing training set file."
)
parser.add_argument(
"--input_filename",
type=str,
help="name of file containing preprocessed, training data."
)
parser.add_argument(
"--output_folder",
type=str,
help="path to output *folder* containing the trained model."
)
parser.add_argument(
"--output_filename",
type=str,
help="name of file containing the trained model."
)
args = parser.parse_args()
return args
def read_and_train (
input_folder: str,
input_filename: str,
output_folder: str,
output_filename: str,
):
"""Reads training data, trains model, and saves it.
Parameters
----------
input_folder: str
Path to preprocessed training data folder containing training set file.
input_filename: str
Name of file containing preprocessed, training data.
output_folder: str
Path to output folder containing the trained model.
output_filename: str
Name of file containing the trained model.
"""
df = pd.read_csv (f"{input_folder}/{input_filename}", index_col=0)
model = train_model (df)
joblib.dump (model, f"{output_folder}/{output_filename}")
def main():
"""Main function of the script."""
args = parse_args ()
read_and_train (
args.input_folder,
args.input_filename,
args.output_folder,
args.output_filename,
)
if __name__ == "__main__":
main()Overwriting training/training.py# Component definition and registration
training_command = command(
inputs=dict(
input_folder=Input (type="uri_folder"),
input_filename=Input (type="string"),
output_filename=Input (type="string"),
),
outputs=dict(
output_folder=Output (type="uri_folder"),
),
code=f"./training/", # location of source code: in this case, the root folder
command="python training.py "
"--input_folder ${{inputs.input_folder}} "
"--input_filename ${{inputs.input_filename}} "
"--output_folder ${{outputs.output_folder}} "
"--output_filename ${{inputs.output_filename}}",
environment="AzureML-sklearn-1.0-ubuntu20.04-py38-cpu@latest",
display_name="Training",
)
training_component = ml_client.create_or_update(training_command.component)Uploading training (0.0 MBs): 100%|██████████| 2309/2309 [00:00<00:00, 50917.16it/s]
%%writefile inference/inference.py
import argparse
from typing import Tuple
import joblib
import pandas as pd
from sklearn.metrics import DistanceMetric
import numpy as np
def inference (
model: Tuple[np.ndarray, np.ndarray],
df: pd.DataFrame,
):
"""Runs dummy inference on new data `df`.
Parameters
----------
model: Tople (np.ndarray, np.ndarray)
Average across rows (one per column), and
standard deviation across rows (one per column).
df: DataFrame
Test data frame on which to perform inference.
Returns
-------
DataFrame
One column dataframe giving an approximation of the Mahalanobis distance
between each row vector and the mean vector, assuming that the covariance
matrix is diagonal. The negative of the scores obtained can be considered
as a sort of prediction probability for each row of belonging to the Gaussian
class estimated from the training data. In this sense this function provides
inference about how "normal" the test samples are.
"""
(mu, std) = model
dist = DistanceMetric.get_metric('mahalanobis', V=np.diag(std**2))
ndims = df.shape[1]
mah_dist = dist.pairwise (mu.reshape(1, ndims), df)
mah_dist = pd.DataFrame (mah_dist.ravel(), columns=["distance"])
print ("Inference result:")
print (mah_dist)
return mah_dist
def parse_args ():
"""Parses input arguments"""
parser = argparse.ArgumentParser()
parser.add_argument(
"--preprocessed_input_folder",
type=str,
help="path to input, preprocessed, test data folder, "
"containing file on which to perform inference."
)
parser.add_argument(
"--preprocessed_input_filename",
type=str,
help="name of file containing the input, preprocessed, test data."
)
parser.add_argument(
"--model_input_folder",
type=str,
help="path to model folder."
)
parser.add_argument(
"--model_input_filename",
type=str,
help="name of model file."
)
parser.add_argument(
"--output_folder",
type=str,
help="path to output data *folder* with inference results."
)
parser.add_argument(
"--output_filename",
type=str,
help="name of file containing the output data with inference results."
)
args = parser.parse_args()
args = parser.parse_args()
return args
def read_and_inference (
preprocessed_input_folder: str,
preprocessed_input_filename: str,
model_input_folder: str,
model_input_filename: str,
output_folder: str,
output_filename: str,
):
"""
Reads test data and model, performs inference, and writes to output inference file.
Parameters
----------
preprocessed_input_folder: str
Path to test (preprocessed) data folder.
preprocessed_input_filename: str
Name of test data file.
model_input_folder: str
Path to built model folder.
model_input_filename: str
Path to inference result folder.
output_folder: str
Path to output data folder with inference results.
output_filename: str
Name of file containing the output data with inference results.
"""
df = pd.read_csv (f"{preprocessed_input_folder}/{preprocessed_input_filename}", index_col=0)
model = joblib.load (f"{model_input_folder}/{model_input_filename}")
z_df = inference (model, df)
z_df.to_csv (f"{output_folder}/{output_filename}")
def main():
"""Main function of the script."""
args = parse_args ()
read_and_inference (
preprocessed_input_folder=args.preprocessed_input_folder,
preprocessed_input_filename=args.preprocessed_input_filename,
model_input_folder=args.model_input_folder,
model_input_filename=args.model_input_filename,
output_folder=args.output_folder,
output_filename=args.output_filename,
)
if __name__ == "__main__":
main()Overwriting inference/inference.pyinference_command = command(
inputs=dict(
preprocessed_input_folder=Input (type="uri_folder"),
preprocessed_input_filename=Input (type="string"),
model_input_folder=Input (type="uri_folder"),
model_input_filename=Input (type="string"),
output_filename=Input (type="string"),
),
outputs=dict(
output_folder=Output (type="uri_folder"),
),
code=f"./inference/", # location of source code: in this case, the root folder
command="python inference.py "
"--preprocessed_input_folder ${{inputs.preprocessed_input_folder}} "
"--preprocessed_input_filename ${{inputs.preprocessed_input_filename}} "
"--model_input_folder ${{inputs.model_input_folder}} "
"--model_input_filename ${{inputs.model_input_filename}} "
"--output_folder ${{outputs.output_folder}} "
"--output_filename ${{inputs.output_filename}} ",
environment="AzureML-sklearn-1.0-ubuntu20.04-py38-cpu@latest",
display_name="inference",
)
inference_component = ml_client.create_or_update(inference_command.component)Uploading inference (0.0 MBs): 100%|██████████| 4046/4046 [00:00<00:00, 151355.71it/s]
Before submitting the pipeline job, it is very important to test it first, ideally with some dummy or small dataset. For this purpose, in the component implementation above, we have separated the code related with argument parsing and the rest of the code, which is in encapsulated in a function called read_and_<...>. This way, we can easily write a test pipeline before implementing the final one, as follows:
# We will need to change the code as we iteratively refine it
# while testing the pipeline. For that purpose, we use the
# reload module
from importlib import reload
from preprocessing import preprocessing
from training import training
from inference import inference
reload (preprocessing)
reload (training)
reload (inference)
def test_pipeline (
# Preprocessing component parameters, first component:
preprocessing_training_input_file: str,
preprocessing_training_output_folder: str, # Not present in final pipeline
preprocessing_training_output_filename: str,
x: int,
# Preprocessing component parameters, second component:
preprocessing_test_input_file: str,
preprocessing_test_output_folder: str, # Not present in final pipeline
preprocessing_test_output_filename: str,
# Training component parameters:
# input_folder: this is preprocessing_training_output_folder
# input_filename: this is preprocessing_training_output_filename
training_output_folder: str, # Not present in final pipeline
training_output_filename: str,
# Inference component parameters:
# preprocessed_input_folder: this is preprocessing_test_output_folder
# preprocessed_input_filename: this is preprocessing_test_output_filename
# model_input_folder: this is training_output_folder
# model_input_filename: this is training_output_filename
inference_output_folder: str, # Not present in final pipeline
inference_output_filename: str,
):
"""
Tests third pipeline: preprocessing, training and inference.
Parameters
----------
preprocessing_training_input_file: str
Path to file containing training data to be preprocessed.
preprocessing_training_output_folder: str
Path to folder containing the preprocessed, training data file.
Not present in final pipeline.
preprocessing_training_output_filename: str
Name of file containing the preprocessed, training data.
x: int
Number to add to input data for preprocessing it.
preprocessing_test_input_file: str
Path to file containing test data to be preprocessed.
preprocessing_test_output_folder: str
Path to folder containing the preprocessed, test data file.
Not present in final pipeline.
preprocessing_test_output_filename: str
Name of file containing the preprocessed, test data.
training_output_folder: str
Path to output folder containing the trained model.
Not present in final pipeline.
training_output_filename: str
Name of file containing the trained model.
inference_output_folder: str
Path to output data folder with inference results.
Not present in final pipeline.
inference_output_filename: str
Name of file containing the output data with inference results.
"""
preprocessing.read_and_preprocess (
input_file=preprocessing_training_input_file,
output_folder=preprocessing_training_output_folder, # Not present in final component
output_filename=preprocessing_training_output_filename,
x=x,
)
preprocessing.read_and_preprocess (
input_file=preprocessing_test_input_file,
output_folder=preprocessing_test_output_folder,
output_filename=preprocessing_test_output_filename,
x=x,
)
training.read_and_train (
input_folder=preprocessing_training_output_folder,
input_filename=preprocessing_training_output_filename,
output_folder=training_output_folder,
output_filename=training_output_filename,
)
inference.read_and_inference (
preprocessed_input_folder=preprocessing_test_output_folder,
preprocessed_input_filename=preprocessing_test_output_filename,
model_input_folder=training_output_folder,
model_input_filename=training_output_filename,
output_folder=inference_output_folder,
output_filename=inference_output_filename,
)
os.makedirs ("test_pipeline", exist_ok=True)
test_pipeline (
# first preprocessing component
preprocessing_training_input_file="./data/dummy_input.csv",
preprocessing_training_output_folder="./test_pipeline", # Not present in final pipeline
preprocessing_training_output_filename="preprocessed_data.csv",
x=10,
# second preprocessing component
preprocessing_test_input_file="./data/dummy_test.csv",
preprocessing_test_output_folder="./test_pipeline", # Not present in final pipeline
preprocessing_test_output_filename="preprocessed_test.csv",
# Training component parameters:
training_output_folder="./test_pipeline", # Not present in final pipeline
training_output_filename="model.pk",
# Inference component parameters:
inference_output_folder="./test_pipeline", # Not present in final pipeline
inference_output_filename="inference_result.csv",
)Input
a b
0 1 4
1 2 5
2 3 6
Adding 10 to df
Output
a b
0 11 14
1 12 15
2 13 16
Input
a b
0 11.0 14.1
1 12.1 15.1
2 13.1 16.1
Adding 10 to df
Output
a b
0 21.0 24.1
1 22.1 25.1
2 23.1 26.1
Input
a b
0 11 14
1 12 15
2 13 16
mu:
[12. 15.]
std:
[1. 1.]
Inference result:
distance
0 12.798828
1 14.283557
2 15.697771@dsl.pipeline(
compute="serverless", # "serverless" value runs pipeline on serverless compute
description="E2E hello world pipeline with input",
)
def three_components_pipeline(
# Preprocessing component parameters, first component:
preprocessing_training_input_file: str,
preprocessing_training_output_filename: str,
x: int,
# Preprocessing component parameters, second component:
preprocessing_test_input_file: str,
preprocessing_test_output_filename: str,
# Training component parameters:
training_output_filename: str,
# Inference component parameters:
inference_output_filename: str,
):
"""
Third pipeline: preprocessing, training and inference.
Parameters
----------
preprocessing_training_input_file: str
Path to file containing training data to be preprocessed.
preprocessing_training_output_filename: str
Name of file containing the preprocessed, training data.
x: int
Number to add to input data for preprocessing it.
preprocessing_test_input_file: str
Path to file containing test data to be preprocessed.
preprocessing_test_output_filename: str
Name of file containing the preprocessed, test data.
training_output_filename: str
Name of file containing the trained model.
inference_output_filename: str
Name of file containing the output data with inference results.
"""
# using data_prep_function like a python call with its own inputs
preprocessing_training_job = preprocessing_component(
input_file=preprocessing_training_input_file,
#output_folder: automatically determined
output_filename=preprocessing_training_output_filename,
x=x,
)
preprocessing_test_job = preprocessing_component(
input_file=preprocessing_test_input_file,
#output_folder: automatically determined
output_filename=preprocessing_test_output_filename,
x=x,
)
training_job = training_component(
input_folder=preprocessing_training_job.outputs.output_folder,
input_filename=preprocessing_training_output_filename,
#output_folder: automatically determined
output_filename=training_output_filename,
)
inference_job = inference_component(
preprocessed_input_folder=preprocessing_test_job.outputs.output_folder,
preprocessed_input_filename=preprocessing_test_output_filename,
model_input_folder=training_job.outputs.output_folder,
model_input_filename=training_output_filename,
#output_folder: automatically determined
output_filename=inference_output_filename,
)
three_components_pipeline = three_components_pipeline(
# first preprocessing component
preprocessing_training_input_file=Input(type="uri_file", path="./data/dummy_input.csv"),
preprocessing_training_output_filename="preprocessed_training_data.csv",
x=10,
# second preprocessing component
preprocessing_test_input_file=Input(type="uri_file", path="./data/dummy_test.csv"),
preprocessing_test_output_filename="preprocessed_test_data.csv",
# Training component parameters:
training_output_filename="model.pk",
# Inference component parameters:
inference_output_filename="inference_results.csv",
)
three_components_pipeline_job = ml_client.jobs.create_or_update(
three_components_pipeline,
# Project's name
experiment_name="e2e_three_components_refactored",
)
# ----------------------------------------------------
# Pipeline running
# ----------------------------------------------------
ml_client.jobs.stream(three_components_pipeline_job.name)RunId: blue_sugar_ns1v5dpj4c
Web View: https://ml.azure.com/runs/blue_sugar_ns1v5dpj4c?wsid=/subscriptions/6af6741b-f140-48c2-84ca-027a27365026/resourcegroups/helloworld/workspaces/helloworld
Streaming logs/azureml/executionlogs.txt
========================================
[2024-03-29 09:00:10Z] Completing processing run id 2319106a-3802-4727-8e58-c347521ab38f.
[2024-03-29 09:00:10Z] Completing processing run id caf9c677-ff96-4cd8-ac83-0439f16bc635.
[2024-03-29 09:00:11Z] Completing processing run id 3c7a3956-de79-4e6c-90d1-e012ed8ccaa8.
[2024-03-29 09:00:12Z] Submitting 1 runs, first five are: eeca7330:4a267c73-32ee-451d-9d53-b144842236ee
[2024-03-29 09:00:52Z] Completing processing run id 4a267c73-32ee-451d-9d53-b144842236ee.
Execution Summary
=================
RunId: blue_sugar_ns1v5dpj4c
Web View: https://ml.azure.com/runs/blue_sugar_ns1v5dpj4c?wsid=/subscriptions/6af6741b-f140-48c2-84ca-027a27365026/resourcegroups/helloworld/workspaces/helloworld
Here we can see the resulting pipeline:

Let’s see how to put all the code needed for creating a pipeline into a script.
%%writefile pipeline_input.json
{
"preprocessing_training_input_file": "./data/dummy_input.csv",
"preprocessing_training_output_filename":"preprocessed_training_data.csv",
"x": 10,
"preprocessing_test_input_file": "./data/dummy_test.csv",
"preprocessing_test_output_filename": "preprocessed_test_data.csv",
"training_output_filename": "model.pk",
"inference_output_filename": "inference_results.csv",
"experiment_name": "e2e_three_components_in_script"
}Writing pipeline_input.json%%writefile hello_world_pipeline.py
# -------------------------------------------------------------------------------------
# Imports
# -------------------------------------------------------------------------------------
# Standard imports
import os
import argparse
import json
# Third-party imports
import pandas as pd
from sklearn.utils import Bunch
# AML imports
from azure.ai.ml import (
command,
dsl,
Input,
Output,
MLClient
)
from azure.identity import DefaultAzureCredential
# -------------------------------------------------------------------------------------
# Connection
# -------------------------------------------------------------------------------------
# authenticate
credential = DefaultAzureCredential()
# Get a handle to the workspace
ml_client = MLClient.from_config (
credential=credential
)
# -------------------------------------------------------------------------------------
# Interface for each component
# -------------------------------------------------------------------------------------
# Preprocessing
preprocessing_command = command(
inputs=dict(
input_file=Input (type="uri_file"),
x=Input (type="number"),
output_filename=Input (type="string"),
),
outputs=dict(
output_folder=Output (type="uri_folder"),
),
code=f"./preprocessing/", # location of source code: in this case, the root folder
command="python preprocessing.py "
"--input_file ${{inputs.input_file}} "
"-x ${{inputs.x}} "
"--output_folder ${{outputs.output_folder}} "
"--output_filename ${{inputs.output_filename}}",
environment="AzureML-sklearn-1.0-ubuntu20.04-py38-cpu@latest",
display_name="Pre-processing",
)
preprocessing_component = ml_client.create_or_update(preprocessing_command.component)
# Training
training_command = command(
inputs=dict(
input_folder=Input (type="uri_folder"),
input_filename=Input (type="string"),
output_filename=Input (type="string"),
),
outputs=dict(
output_folder=Output (type="uri_folder"),
),
code=f"./training/", # location of source code: in this case, the root folder
command="python training.py "
"--input_folder ${{inputs.input_folder}} "
"--input_filename ${{inputs.input_filename}} "
"--output_folder ${{outputs.output_folder}} "
"--output_filename ${{inputs.output_filename}}",
environment="AzureML-sklearn-1.0-ubuntu20.04-py38-cpu@latest",
display_name="Training",
)
training_component = ml_client.create_or_update(training_command.component)
# Inference
inference_command = command(
inputs=dict(
preprocessed_input_folder=Input (type="uri_folder"),
preprocessed_input_filename=Input (type="string"),
model_input_folder=Input (type="uri_folder"),
model_input_filename=Input (type="string"),
output_filename=Input (type="string"),
),
outputs=dict(
output_folder=Output (type="uri_folder"),
),
code=f"./inference/", # location of source code: in this case, the root folder
command="python inference.py "
"--preprocessed_input_folder ${{inputs.preprocessed_input_folder}} "
"--preprocessed_input_filename ${{inputs.preprocessed_input_filename}} "
"--model_input_folder ${{inputs.model_input_folder}} "
"--model_input_filename ${{inputs.model_input_filename}} "
"--output_folder ${{outputs.output_folder}} "
"--output_filename ${{inputs.output_filename}} ",
environment="AzureML-sklearn-1.0-ubuntu20.04-py38-cpu@latest",
display_name="inference",
)
inference_component = ml_client.create_or_update(inference_command.component)
# -------------------------------------------------------------------------------------
# Pipeline definition
# -------------------------------------------------------------------------------------
@dsl.pipeline(
compute="serverless", # "serverless" value runs pipeline on serverless compute
description="E2E hello world pipeline with input",
)
def three_components_pipeline(
# Preprocessing component parameters, first component:
preprocessing_training_input_file: str,
preprocessing_training_output_filename: str,
x: int,
# Preprocessing component parameters, second component:
preprocessing_test_input_file: str,
preprocessing_test_output_filename: str,
# Training component parameters:
training_output_filename: str,
# Inference component parameters:
inference_output_filename: str,
):
"""
Third pipeline: preprocessing, training and inference.
Parameters
----------
preprocessing_training_input_file: str
Path to file containing training data to be preprocessed.
preprocessing_training_output_filename: str
Name of file containing the preprocessed, training data.
x: int
Number to add to input data for preprocessing it.
preprocessing_test_input_file: str
Path to file containing test data to be preprocessed.
preprocessing_test_output_filename: str
Name of file containing the preprocessed, test data.
training_output_filename: str
Name of file containing the trained model.
inference_output_filename: str
Name of file containing the output data with inference results.
"""
# using data_prep_function like a python call with its own inputs
preprocessing_training_job = preprocessing_component(
input_file=preprocessing_training_input_file,
#output_folder: automatically determined
output_filename=preprocessing_training_output_filename,
x=x,
)
preprocessing_test_job = preprocessing_component(
input_file=preprocessing_test_input_file,
#output_folder: automatically determined
output_filename=preprocessing_test_output_filename,
x=x,
)
training_job = training_component(
input_folder=preprocessing_training_job.outputs.output_folder,
input_filename=preprocessing_training_output_filename,
#output_folder: automatically determined
output_filename=training_output_filename,
)
inference_job = inference_component(
preprocessed_input_folder=preprocessing_test_job.outputs.output_folder,
preprocessed_input_filename=preprocessing_test_output_filename,
model_input_folder=training_job.outputs.output_folder,
model_input_filename=training_output_filename,
#output_folder: automatically determined
output_filename=inference_output_filename,
)
# -------------------------------------------------------------------------------------
# Pipeline running
# -------------------------------------------------------------------------------------
def run_pipeline (
config_path: str="./pipeline_input.json",
experiment_name="hello-world-experiment",
):
# Read config json file
with open (config_path,"rt") as config_file:
config = json.load (config_file)
# Convert config dictionary into a Bunch object. This is a
# sub-class of dict which allows to get access to fields
# as object attributes (a bit more convenient IMO) in addition
# to also allowing the dict syntax.
config = Bunch (**config)
# Build pipeline
three_components_pipeline_object = three_components_pipeline(
# first preprocessing component
preprocessing_training_input_file=Input(type="uri_file", path=config.preprocessing_training_input_file),
preprocessing_training_output_filename=config.preprocessing_training_output_filename,
x=config.x,
# second preprocessing component
preprocessing_test_input_file=Input(type="uri_file", path=config.preprocessing_test_input_file),
preprocessing_test_output_filename=config.preprocessing_test_output_filename,
# Training component parameters:
training_output_filename=config.training_output_filename,
# Inference component parameters:
inference_output_filename=config.inference_output_filename,
)
three_components_pipeline_job = ml_client.jobs.create_or_update(
three_components_pipeline_object,
# Project's name
experiment_name=experiment_name,
)
# ----------------------------------------------------
# Pipeline running
# ----------------------------------------------------
ml_client.jobs.stream(three_components_pipeline_job.name)
# -------------------------------------------------------------------------------------
# Parsing
# -------------------------------------------------------------------------------------
def parse_args ():
"""Parses input arguments"""
parser = argparse.ArgumentParser()
parser.add_argument (
"--config-path",
type=str,
default="pipeline_input.json",
help="Path to config file specifying pipeline input parameters.",
)
parser.add_argument (
"--experiment-name",
type=str,
default="hello-world-experiment",
help="Name of experiment.",
)
args = parser.parse_args()
return args
# -------------------------------------------------------------------------------------
# main
# -------------------------------------------------------------------------------------
def main ():
"""Parses arguments and runs pipeline"""
args = parse_args ()
run_pipeline (
args.config_path,
args.experiment_name,
)
# -------------------------------------------------------------------------------------
# -------------------------------------------------------------------------------------
if __name__ == "__main__":
main ()Overwriting hello_world_pipeline.pyBad pipe message: %s [b'1~\xd1B\xe9k\xf8\x8beF\x0bi8_~\n\xa2F \xfec\x82\xc3\xb3^P&\xb5A\xd2\xbb\xa6\xb1\xc5\xef\x04\xb7C\xa9\xeb\xb2U\xed\x81\x80M\x05\xf7\x85H\xc8\x00\x08\x13\x02\x13\x03\x13\x01\x00\xff\x01\x00\x00\x8f\x00\x00\x00\x0e\x00\x0c\x00\x00\t127.0.0.1\x00\x0b\x00\x04\x03\x00\x01\x02\x00\n\x00\x0c\x00\n\x00\x1d\x00\x17\x00\x1e\x00\x19\x00\x18\x00#\x00\x00\x00\x16\x00\x00\x00\x17\x00\x00\x00\r\x00\x1e\x00']
Bad pipe message: %s [b'\x03\x05\x03\x06\x03\x08\x07\x08\x08\x08\t\x08\n\x08\x0b\x08\x04\x08\x05\x08\x06\x04\x01\x05\x01\x06\x01']
Bad pipe message: %s [b"\xcd\xe4\xaew\x91`\x94\xc6fO\xea\x92 \xc7b\xb15G\x00\x00|\xc0,\xc00\x00\xa3\x00\x9f\xcc\xa9\xcc\xa8\xcc\xaa\xc0\xaf\xc0\xad\xc0\xa3\xc0\x9f\xc0]\xc0a\xc0W\xc0S\xc0+\xc0/\x00\xa2\x00\x9e\xc0\xae\xc0\xac\xc0\xa2\xc0\x9e\xc0\\\xc0`\xc0V\xc0R\xc0$\xc0(\x00k\x00j\xc0#\xc0'\x00g\x00@\xc0\n\xc0\x14\x009\x008\xc0\t\xc0\x13\x003\x002\x00\x9d\xc0\xa1\xc0\x9d\xc0Q\x00\x9c\xc0\xa0\xc0\x9c\xc0P\x00=\x00<\x005\x00/\x00\x9a\x00\x99\xc0\x07\xc0\x11\x00\x96\x00\x05\x00\xff\x01\x00\x00j\x00\x00\x00\x0e\x00\x0c\x00\x00\t127.0.0.1\x00\x0b\x00\x04\x03\x00\x01\x02\x00\n\x00\x0c\x00\n\x00\x1d\x00\x17\x00\x1e\x00\x19\x00\x18\x00#\x00\x00\x00\x16\x00\x00\x00\x17\x00\x00\x00\r\x000\x00.\x04\x03\x05\x03\x06\x03\x08\x07\x08\x08\x08\t\x08\n\x08\x0b\x08\x04\x08\x05\x08\x06\x04\x01\x05\x01\x06\x01\x03\x03\x02\x03\x03\x01\x02\x01\x03", b'\x02']
Bad pipe message: %s [b'\x05\x02\x06']
Bad pipe message: %s [b'\x0b"a7\xfa\xa1#\xf3\x88\xcc%\xae\xb45\xbc\xdbY\xb8\x00\x00\xa6\xc0,\xc00\x00\xa3\x00\x9f\xcc\xa9\xcc\xa8\xcc\xaa\xc0\xaf\xc0\xad\xc0\xa3\xc0\x9f\xc0]\xc0a\xc0W\xc0S\xc0+\xc0/\x00\xa2\x00\x9e\xc0\xae\xc0\xac\xc0\xa2\xc0\x9e\xc0\\\xc0`\xc0V\xc0R\xc0$\xc0(\x00k\x00j\xc0s\xc0w\x00\xc4\x00\xc3\xc0#\xc0\'\x00g\x00@\xc0r\xc0v\x00\xbe\x00\xbd\xc0\n\xc0\x14\x009\x008\x00\x88\x00\x87\xc0\t\xc0\x13\x003\x002\x00\x9a\x00\x99\x00E\x00D\xc0\x07\xc0\x11\xc0\x08\xc0\x12\x00\x16\x00\x13\x00\x9d\xc0\xa1\xc0\x9d\xc0Q\x00\x9c\xc0\xa0\xc0\x9c\xc0P\x00=\x00\xc0\x00<\x00\xba\x005\x00\x84\x00/\x00\x96\x00A\x00\x05\x00']
Bad pipe message: %s [b'\xff\x01\x00\x00j\x00\x00\x00\x0e']
Bad pipe message: %s [b'7\x992kK\xc1\xdbF\x8b\xb1\xe1l\x19\xbfA<\x1fc\x00\x00>\xc0\x14\xc0\n\x009\x008\x007\x006\xc0\x0f\xc0\x05\x005\xc0\x13\xc0\t\x003\x002\x001\x000\xc0\x0e\xc0\x04\x00/\x00\x9a\x00\x99\x00\x98\x00\x97\x00\x96\x00\x07\xc0\x11\xc0\x07\xc0\x0c\xc0\x02\x00\x05\x00\x04\x00\xff\x02\x01\x00\x00C\x00\x00\x00\x0e\x00\x0c\x00\x00\t127.0.0.1\x00\x0b\x00\x04\x03\x00\x01\x02']
Bad pipe message: %s [b'\xcf\xf4\xe1\xe6\xec\xa7$\x0f\x95\xd8\xe3X\xfcm\x93\xc2\x06?\x00\x00\xa2\xc0\x14\xc0\n\x009\x008\x007\x006\x00\x88\x00\x87\x00\x86\x00\x85\xc0\x19\x00:\x00\x89\xc0\x0f\xc0\x05\x005\x00\x84\xc0\x13\xc0\t\x003\x002\x001\x000\x00\x9a\x00\x99\x00\x98\x00\x97\x00E\x00D\x00C\x00B\xc0\x18\x004\x00\x9b\x00F\xc0\x0e\xc0\x04\x00/\x00\x96\x00A\x00\x07\xc0\x11\xc0\x07\xc0\x16\x00\x18\xc0\x0c\xc0\x02\x00\x05\x00\x04\xc0\x12\xc0\x08\x00\x16\x00\x13\x00', b'\r\xc0\x17\x00\x1b\xc0\r\xc0\x03\x00\n\x00\x15\x00\x12']
Bad pipe message: %s [b'Nv\xa8\xf4\x13\xe0t\x12q\xe1\xb8\xa4\xe0(\xaflvv']
Bad pipe message: %s [b'\xd5\xc3({`3.\xe2\xad\xa8.6\x01\xe9\xb4\x06\xba\xb1\x00\x00>\xc0\x14\xc0\n\x009\x008\x007\x006\xc0\x0f\xc0\x05\x005\xc0\x13\xc0\t\x003\x002\x001\x000\xc0\x0e\xc0\x04\x00/\x00\x9a\x00\x99\x00\x98\x00\x97\x00\x96\x00\x07\xc0\x11\xc0\x07\xc0\x0c\xc0\x02\x00\x05\x00\x04\x00\xff\x02\x01\x00\x15\x03\x00']
Bad pipe message: %s [b"\xa7\xe2\x12\x89\xeaUh\xb9\x1a\xc3\x92\x85\x1f\xd4\xf7\xaf\xb4\xcd\x00\x00\x86\xc00\xc0,\xc0(\xc0$\xc0\x14\xc0\n\x00\xa5\x00\xa3\x00\xa1\x00\x9f\x00k\x00j\x00i\x00h\x009\x008\x007\x006\xc02\xc0.\xc0*\xc0&\xc0\x0f\xc0\x05\x00\x9d\x00=\x005\xc0/\xc0+\xc0'\xc0#\xc0\x13\xc0\t\x00\xa4\x00\xa2\x00\xa0\x00\x9e\x00g\x00@\x00?\x00>\x003\x002\x001\x000\xc01\xc0-\xc0)\xc0%\xc0\x0e\xc0\x04\x00\x9c\x00<\x00/\x00\x9a\x00\x99\x00\x98\x00\x97\x00\x96\x00\x07\xc0\x11\xc0\x07\xc0\x0c\xc0\x02\x00\x05\x00\x04\x00\xff\x02\x01\x00\x00g\x00\x00\x00\x0e\x00\x0c\x00\x00\t127.0.0.1\x00\x0b\x00\x04\x03\x00\x01\x02\x00\n\x00\x1c\x00\x1a\x00\x17\x00\x19\x00\x1c\x00\x1b\x00\x18\x00\x1a\x00\x16\x00\x0e\x00\r\x00\x0b\x00\x0c\x00\t\x00\n\x00#\x00\x00\x00\r\x00 \x00\x1e\x06\x01\x06\x02\x06\x03\x05\x01\x05\x02\x05\x03\x04\x01\x04\x02", b'\x03\x01\x03', b'\x03', b'\x02', b'\x03']
Bad pipe message: %s [b'\xc7\x95X[|\x00\xb9,o\xa7\x95\xdd\xee\xd3A\xd2g\x06\x00\x00\xf4\xc00\xc0,\xc0(\xc0$\xc0\x14\xc0\n\x00\xa5\x00\xa3\x00\xa1\x00\x9f\x00k\x00j\x00i\x00h\x009\x008\x007\x006\x00\x88\x00\x87\x00\x86\x00\x85\xc0\x19\x00\xa7\x00', b":\x00\x89\xc02\xc0.\xc0*\xc0&\xc0\x0f\xc0\x05\x00\x9d\x00=\x005\x00\x84\xc0/\xc0+\xc0'\xc0#\xc0\x13\xc0\t\x00\xa4\x00\xa2\x00\xa0\x00\x9e\x00g\x00@\x00?\x00>\x003\x002\x001\x000\x00\x9a\x00\x99\x00\x98\x00\x97\x00E\x00D\x00C\x00B\xc0\x18\x00\xa6\x00l\x004\x00\x9b\x00F\xc01\xc0-\xc0)\xc0%\xc0\x0e\xc0\x04\x00\x9c\x00<\x00/\x00\x96\x00"]
Bad pipe message: %s [b'\x07\xc0\x11\xc0\x07\xc0\x16\x00\x18\xc0\x0c\xc0\x02\x00\x05\x00\x04\xc0\x12\xc0\x08\x00\x16\x00\x13\x00\x10\x00\r\xc0\x17\x00\x1b\xc0\r\xc0\x03\x00\n\x00\x15\x00\x12\x00\x0f\x00\x0c\x00\x1a\x00\t\x00\x14\x00\x11\x00\x19\x00\x08\x00\x06\x00\x17\x00']
Bad pipe message: %s [b'\x10\xc0']
Bad pipe message: %s [b'\x15\xc0\x0b\xc0\x01']We can now run the script from command line:
First we open up a terminal and activate a conda environment that uses the python SDK version 2. Let’s see what environments we currently have:
conda env listAs of now, this provides the following list:
# conda environments:
#
base /anaconda
azureml_py310_sdkv2 /anaconda/envs/azureml_py310_sdkv2
azureml_py38 * /anaconda/envs/azureml_py38
azureml_py38_PT_TF /anaconda/envs/azureml_py38_PT_TF
jupyter_env /anaconda/envs/jupyter_envFrom that list, the conda environment using SDK v2 is azureml_py310_sdkv2 (use another if that changes when you read this)
We activate it and run our script:
conda activate azureml_py310_sdkv2
python hello_world_pipeline.pyLet’s introduce two optional changes:
preprocessing_command, training_command and inference_command out of the pipeline function, we will define them inside.ml_client.create_or_update (my_component_command.component), as it was done for example here:preprocessing_component = ml_client.create_or_update(preprocessing_command.component)%%writefile hello_world_pipeline.py
# -------------------------------------------------------------------------------------
# Imports
# -------------------------------------------------------------------------------------
# Standard imports
import os
import argparse
import json
# Third-party imports
import pandas as pd
from sklearn.utils import Bunch
# AML imports
from azure.ai.ml import (
command,
dsl,
Input,
Output,
MLClient
)
from azure.identity import DefaultAzureCredential
# -------------------------------------------------------------------------------------
# Connection
# -------------------------------------------------------------------------------------
def connect ():
# authenticate
credential = DefaultAzureCredential()
# Get a handle to the workspace
ml_client = MLClient.from_config (
credential=credential,
)
return ml_client
# -------------------------------------------------------------------------------------
# Pipeline definition
# -------------------------------------------------------------------------------------
@dsl.pipeline(
compute="serverless", # "serverless" value runs pipeline on serverless compute
description="E2E hello world pipeline with input",
)
def three_components_pipeline(
# Preprocessing component parameters, first component:
preprocessing_training_input_file: str,
preprocessing_training_output_filename: str,
x: int,
# Preprocessing component parameters, second component:
preprocessing_test_input_file: str,
preprocessing_test_output_filename: str,
# Training component parameters:
training_output_filename: str,
# Inference component parameters:
inference_output_filename: str,
):
"""
Third pipeline: preprocessing, training and inference.
Parameters
----------
preprocessing_training_input_file: str
Path to file containing training data to be preprocessed.
preprocessing_training_output_filename: str
Name of file containing the preprocessed, training data.
x: int
Number to add to input data for preprocessing it.
preprocessing_test_input_file: str
Path to file containing test data to be preprocessed.
preprocessing_test_output_filename: str
Name of file containing the preprocessed, test data.
training_output_filename: str
Name of file containing the trained model.
inference_output_filename: str
Name of file containing the output data with inference results.
"""
print (
"Running hello-world pipeline with args",
preprocessing_training_input_file,
preprocessing_training_output_filename,
x,
preprocessing_test_input_file,
preprocessing_test_output_filename,
training_output_filename,
inference_output_filename,
sep="\n",
)
# -------------------------------------------------------------------------------------
# Preprocessing
# -------------------------------------------------------------------------------------
# Interface
preprocessing_component = command(
inputs=dict(
input_file=Input (type="uri_file"),
x=Input (type="number"),
output_filename=Input (type="string"),
),
outputs=dict(
output_folder=Output (type="uri_folder"),
),
code=f"./preprocessing/", # location of source code: in this case, the root folder
command="python preprocessing.py "
"--input_file ${{inputs.input_file}} "
"-x ${{inputs.x}} "
"--output_folder ${{outputs.output_folder}} "
"--output_filename ${{inputs.output_filename}}",
environment="AzureML-sklearn-1.0-ubuntu20.04-py38-cpu@latest",
display_name="Pre-processing",
)
# Instantiation
preprocessing_training_job = preprocessing_component(
input_file=preprocessing_training_input_file,
#output_folder: automatically determined
output_filename=preprocessing_training_output_filename,
x=x,
)
preprocessing_test_job = preprocessing_component(
input_file=preprocessing_test_input_file,
#output_folder: automatically determined
output_filename=preprocessing_test_output_filename,
x=x,
)
# -------------------------------------------------------------------------------------
# Training component
# -------------------------------------------------------------------------------------
# Interface
training_component = command(
inputs=dict(
input_folder=Input (type="uri_folder"),
input_filename=Input (type="string"),
output_filename=Input (type="string"),
),
outputs=dict(
output_folder=Output (type="uri_folder"),
),
code=f"./training/", # location of source code: in this case, the root folder
command="python training.py "
"--input_folder ${{inputs.input_folder}} "
"--input_filename ${{inputs.input_filename}} "
"--output_folder ${{outputs.output_folder}} "
"--output_filename ${{inputs.output_filename}}",
environment="AzureML-sklearn-1.0-ubuntu20.04-py38-cpu@latest",
display_name="Training",
)
# Instantiation
training_job = training_component(
input_folder=preprocessing_training_job.outputs.output_folder,
input_filename=preprocessing_training_output_filename,
#output_folder: automatically determined
output_filename=training_output_filename,
)
# -------------------------------------------------------------------------------------
# Inference
# -------------------------------------------------------------------------------------
# Interface
inference_component = command(
inputs=dict(
preprocessed_input_folder=Input (type="uri_folder"),
preprocessed_input_filename=Input (type="string"),
model_input_folder=Input (type="uri_folder"),
model_input_filename=Input (type="string"),
output_filename=Input (type="string"),
),
outputs=dict(
output_folder=Output (type="uri_folder"),
),
code=f"./inference/", # location of source code: in this case, the root folder
command="python inference.py "
"--preprocessed_input_folder ${{inputs.preprocessed_input_folder}} "
"--preprocessed_input_filename ${{inputs.preprocessed_input_filename}} "
"--model_input_folder ${{inputs.model_input_folder}} "
"--model_input_filename ${{inputs.model_input_filename}} "
"--output_folder ${{outputs.output_folder}} "
"--output_filename ${{inputs.output_filename}} ",
environment="AzureML-sklearn-1.0-ubuntu20.04-py38-cpu@latest",
display_name="inference",
)
# Instantiation
inference_job = inference_component(
preprocessed_input_folder=preprocessing_test_job.outputs.output_folder,
preprocessed_input_filename=preprocessing_test_output_filename,
model_input_folder=training_job.outputs.output_folder,
model_input_filename=training_output_filename,
#output_folder: automatically determined
output_filename=inference_output_filename,
)
# -------------------------------------------------------------------------------------
# Pipeline running
# -------------------------------------------------------------------------------------
def run_pipeline (
config_path: str="./pipeline_input.json",
experiment_name="hello-world-experiment",
):
# Read config json file
with open (config_path,"rt") as config_file:
config = json.load (config_file)
# Convert config dictionary into a Bunch object.
# This allows to get access to fields as object attributes
# Which I find more convenient.
config = Bunch (**config)
# Connect to AML client
ml_client = connect ()
# Build pipeline
three_components_pipeline_object = three_components_pipeline(
# first preprocessing component
preprocessing_training_input_file=Input(type="uri_file", path=config.preprocessing_training_input_file),
preprocessing_training_output_filename=config.preprocessing_training_output_filename,
x=config.x,
# second preprocessing component
preprocessing_test_input_file=Input(type="uri_file", path=config.preprocessing_test_input_file),
preprocessing_test_output_filename=config.preprocessing_test_output_filename,
# Training component parameters:
training_output_filename=config.training_output_filename,
# Inference component parameters:
inference_output_filename=config.inference_output_filename,
)
three_components_pipeline_job = ml_client.jobs.create_or_update(
three_components_pipeline_object,
# Project's name
experiment_name=experiment_name,
)
# ----------------------------------------------------
# Pipeline running
# ----------------------------------------------------
ml_client.jobs.stream(three_components_pipeline_job.name)
# -------------------------------------------------------------------------------------
# Parsing
# -------------------------------------------------------------------------------------
def parse_args ():
"""Parses input arguments"""
parser = argparse.ArgumentParser()
parser.add_argument (
"--config-path",
type=str,
default="pipeline_input.json",
help="Path to config file specifying pipeline input parameters.",
)
parser.add_argument (
"--experiment-name",
type=str,
default="hello-world-experiment",
help="Name of experiment.",
)
args = parser.parse_args()
print ("Running hello-world pipeline with args", args)
return args
# -------------------------------------------------------------------------------------
# main
# -------------------------------------------------------------------------------------
def main ():
"""Parses arguments and runs pipeline"""
args = parse_args ()
run_pipeline (
args.config_path,
args.experiment_name,
)
# -------------------------------------------------------------------------------------
# -------------------------------------------------------------------------------------
if __name__ == "__main__":
main ()Overwriting hello_world_pipeline.pySo far we have been using a serverless compute, where Azure automatically creates the compute instances needed for running the pipeline, scaling and deleting them as required. More information can be found here. In this section we opt to use a specific compute instance. This has some advantages: while the serveless mode can shut down our compute when idle, and needs to start it again when new loads arrive, with a compute instance we can ensure that the instance is always running and the functions loaded, which may be important in time critical situations. More information can be found here.
In addition to this change, we will also us make the code a bit more modular and reusable. We do so by: - Indicating custom environments that can be adapted to different requirements. - Defining different functions that: - Connect to the AML workspace. - Create the environment. - Create the pipeline. - Set up and run the created pipeline.
We will separate the functions into two different files: an aml_utils.py module where we include functions that can be reused across different pipelines, and a hello_world.py script where we have code specific for our “Hello World” pipeline.
Let us start with the aml_utils.py file. We will be writing the consecutive functions one after the other, appending them together with the magic command %%writefile -a aml_utils.py, which appends when we pass the flag -a.
We start with the imports:
%%writefile aml_utils.py
# Standard imports
import json
# Third-party imports
from sklearn.utils import Bunch
# AML imports
from azure.ai.ml import MLClient
from azure.ai.ml.entities import Environment
from azure.identity import DefaultAzureCredential
Overwriting aml_utils.pyWe encapsulate the code for connecting to AML in a separate function, which we append to the previous code:
%%writefile -a aml_utils.py
def connect ():
"""Connects to Azure ML workspace and returns a handle to use it."""
# authenticate
credential = DefaultAzureCredential()
# Get a handle to the workspace
ml_client = MLClient.from_config (
credential=credential,
)
return ml_client
Appending to aml_utils.pyUntil now, we have been using environment="AzureML-sklearn-1.0-ubuntu20.04-py38-cpu@latest" when defining our component interfaces with the command function. This is one of the environments alreadyt available in the Azure ML studio, and it allows us to use scikit-learn as well as azure ml libraries on a ubuntu20.0.04 OS. Let us create a custom environment instead:
%%writefile hello_world.yml
name: hello-world
dependencies:
- python=3.10
- pip
- pandas
- numpy
- pip:
- scikit-learn
- joblib
- azure-ai-mlOverwriting hello_world.ymlAvailable docker images can be found here. With this, we can define our envioroment as follows:
%%writefile -a aml_utils.py
def create_env (
ml_client,
image: str="mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04",
conda_file: str="./pipeline.yml",
name_env: str="pipeline",
description_env: str="Pipeline environment",
):
"Creates environment in AML workspace"
env = Environment (
image=image,
conda_file=conda_file,
name=name_env,
description=description_env,
)
ml_client.environments.create_or_update (env)
Appending to aml_utils.pyAfter this, we can replace the name of our environment in the command functions that we will use belowfor defining the interface of each component, for instance as follows:
preprocessing_component = command(
...
environment="hello-world@latest",
...
)The compute instance can be indicated with just one line of code, which will be included in the function described in next subsection, called connect_setup_and_run:
# change this with the name of your compute instance in AML
pipeline.settings.default_compute = "my-compute-instance" We will also need to remove the argument compute="serverless" from the pipeline decorator, as we will see below when we define our pipeline function.
We now define a connect_setup_and_run where we put all the necessary code for setting up and running any pipeline previously created. The function also connects to the AML workspace by calling connect above:
%%writefile -a aml_utils.py
def connect_setup_and_run (
pipeline_object,
experiment_name: str="pipeline experiment",
compute_name: str="jaumecpu",
image: str="mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04",
conda_file: str="./pipeline.yml",
name_env: str="pipeline",
description_env: str="Pipeline environment",
):
"""Does all the setup required to run the pipeline.
This includes: connecting, creating environment, indicating our compute instance,
creating and running the pipeline.
"""
# connect
ml_client = connect ()
# create env
create_env (
ml_client,
image=image,
conda_file=conda_file,
name_env=name_env,
description_env=description_env,
)
# compute
pipeline_object.settings.default_compute = compute_name
# create pipeline and run
pipeline_job = ml_client.jobs.create_or_update(
pipeline_object,
# Project's name
experiment_name=experiment_name,
)
# ----------------------------------------------------
# Pipeline running
# ----------------------------------------------------
ml_client.jobs.stream(pipeline_job.name)
Appending to aml_utils.pyFinally, we will write a helper function that reads the configuration from a json file and converts the resulting dictionary into a Bunch object. The Bunch class inherits from the standard dict class, and allows to get access to each dictionary field as if it was an object attribute. It also allows to get access to the dict fields in the standard way. For instance, both:
x = my_bunch.my_field
my_bunch.my_field = x+1and
x = my_bunch["my_field"]
my_bunch["my_field"] = x + 1are equivalent.
Here is the resulting read_config function:
%%writefile -a aml_utils.py
def read_config (config_path: str):
# Read config json file
with open (config_path,"rt") as config_file:
config = json.load (config_file)
config = Bunch (**config)
return configAppending to aml_utils.pyIn this section, we use a config file that is the same as the one in the previous section (“Putting everything into a script”), but adding the following parameters:
"compute_name": "jaumecpu",
"image" = "mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04",
"conda_file"="./hello_world.yml",
"description_env"="Hello World" The added parameters indicate the compute instance and environment details. The final config file is as follows:
%%writefile pipeline_input.json
{
"preprocessing_training_input_file": "./data/dummy_input.csv",
"preprocessing_training_output_filename":"preprocessed_training_data.csv",
"x": 10,
"preprocessing_test_input_file": "./data/dummy_test.csv",
"preprocessing_test_output_filename": "preprocessed_test_data.csv",
"training_output_filename": "model.pk",
"inference_output_filename": "inference_results.csv",
"experiment_name": "e2e_three_components_in_script",
"compute_name": "jaumecpu",
"image": "mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04",
"conda_file": "./hello_world.yml",
"name_env": "hello-world",
"description_env": "Hello World"
}Overwriting pipeline_input.jsonLet us know write the functions that are specific for our current pipeline. We do so in the script that we will be running from command line, hello_world_pipeline.py.
Let us start again with the imports section:
%%writefile hello_world_pipeline.py
# Standard imports
import argparse
# AML imports
from azure.ai.ml import (
command,
dsl,
Input,
Output,
)
# Utility functions
from aml_utils import (
connect,
create_env,
connect_setup_and_run,
read_config,
)
We write next our pipeline function, which indicates the components to be used and how they are connected throug inputs and outputs. The only change with respect to previous pipeline functions is that we indicate as environment the one we just created, “hello-world”, when we describe each component through the command function. The rest doesn’t change.
%%writefile -a hello_world_pipeline.py
@dsl.pipeline(
description="E2E hello world pipeline with input",
)
def three_components_pipeline(
# Preprocessing component parameters, first component:
preprocessing_training_input_file: str,
preprocessing_training_output_filename: str,
x: int,
# Preprocessing component parameters, second component:
preprocessing_test_input_file: str,
preprocessing_test_output_filename: str,
# Training component parameters:
training_output_filename: str,
# Inference component parameters:
inference_output_filename: str,
):
"""
Third pipeline: preprocessing, training and inference.
Parameters
----------
preprocessing_training_input_file: str
Path to file containing training data to be preprocessed.
preprocessing_training_output_filename: str
Name of file containing the preprocessed, training data.
x: int
Number to add to input data for preprocessing it.
preprocessing_test_input_file: str
Path to file containing test data to be preprocessed.
preprocessing_test_output_filename: str
Name of file containing the preprocessed, test data.
training_output_filename: str
Name of file containing the trained model.
inference_output_filename: str
Name of file containing the output data with inference results.
"""
# -------------------------------------------------------------------------------------
# Preprocessing
# -------------------------------------------------------------------------------------
# Interface
preprocessing_component = command(
inputs=dict(
input_file=Input (type="uri_file"),
x=Input (type="number"),
output_filename=Input (type="string"),
),
outputs=dict(
output_folder=Output (type="uri_folder"),
),
code=f"./preprocessing/", # location of source code: in this case, the root folder
command="python preprocessing.py "
"--input_file ${{inputs.input_file}} "
"-x ${{inputs.x}} "
"--output_folder ${{outputs.output_folder}} "
"--output_filename ${{inputs.output_filename}}",
environment="hello-world@latest",
display_name="Pre-processing",
)
# Instantiation
preprocessing_training_job = preprocessing_component(
input_file=preprocessing_training_input_file,
#output_folder: automatically determined
output_filename=preprocessing_training_output_filename,
x=x,
)
preprocessing_test_job = preprocessing_component(
input_file=preprocessing_test_input_file,
#output_folder: automatically determined
output_filename=preprocessing_test_output_filename,
x=x,
)
# -------------------------------------------------------------------------------------
# Training component
# -------------------------------------------------------------------------------------
# Interface
training_component = command(
inputs=dict(
input_folder=Input (type="uri_folder"),
input_filename=Input (type="string"),
output_filename=Input (type="string"),
),
outputs=dict(
output_folder=Output (type="uri_folder"),
),
code=f"./training/", # location of source code: in this case, the root folder
command="python training.py "
"--input_folder ${{inputs.input_folder}} "
"--input_filename ${{inputs.input_filename}} "
"--output_folder ${{outputs.output_folder}} "
"--output_filename ${{inputs.output_filename}}",
environment="hello-world@latest",
display_name="Training",
)
# Instantiation
training_job = training_component(
input_folder=preprocessing_training_job.outputs.output_folder,
input_filename=preprocessing_training_output_filename,
#output_folder: automatically determined
output_filename=training_output_filename,
)
# -------------------------------------------------------------------------------------
# Inference
# -------------------------------------------------------------------------------------
# Interface
inference_component = command(
inputs=dict(
preprocessed_input_folder=Input (type="uri_folder"),
preprocessed_input_filename=Input (type="string"),
model_input_folder=Input (type="uri_folder"),
model_input_filename=Input (type="string"),
output_filename=Input (type="string"),
),
outputs=dict(
output_folder=Output (type="uri_folder"),
),
code=f"./inference/", # location of source code: in this case, the root folder
command="python inference.py "
"--preprocessed_input_folder ${{inputs.preprocessed_input_folder}} "
"--preprocessed_input_filename ${{inputs.preprocessed_input_filename}} "
"--model_input_folder ${{inputs.model_input_folder}} "
"--model_input_filename ${{inputs.model_input_filename}} "
"--output_folder ${{outputs.output_folder}} "
"--output_filename ${{inputs.output_filename}} ",
environment="hello-world@latest",
display_name="inference",
)
# Instantiation
inference_job = inference_component(
preprocessed_input_folder=preprocessing_test_job.outputs.output_folder,
preprocessed_input_filename=preprocessing_test_output_filename,
model_input_folder=training_job.outputs.output_folder,
model_input_filename=training_output_filename,
#output_folder: automatically determined
output_filename=inference_output_filename,
)
Next we define a function that both creates and runs the pipeline implemented above. This function performs all the steps implemented so far: it reads a config file, instantiates a pipeline object by calling our three_components_pipeline function, and finally performs the pipeline set-up and runs it by calling connect_setup_and_run:
%%writefile -a hello_world_pipeline.py
def run_pipeline (
config_path: str="./pipeline_input.json",
experiment_name="hello-world-experiment",
):
# read config
config = read_config (config_path)
# Build pipeline
three_components_pipeline_object = three_components_pipeline(
# first preprocessing component
preprocessing_training_input_file=Input(type="uri_file", path=config.preprocessing_training_input_file),
preprocessing_training_output_filename=config.preprocessing_training_output_filename,
x=config.x,
# second preprocessing component
preprocessing_test_input_file=Input(type="uri_file", path=config.preprocessing_test_input_file),
preprocessing_test_output_filename=config.preprocessing_test_output_filename,
# Training component parameters:
training_output_filename=config.training_output_filename,
# Inference component parameters:
inference_output_filename=config.inference_output_filename,
# name env:
name_env=config.name_env,
)
connect_setup_and_run (
three_components_pipeline_object,
experiment_name=experiment_name,
compute_name=config.compute_name,
image=config.image,
conda_file=config.conda_file,
name_env=config.name_env,
description_env=config.description_env,
)
Overwriting hello_world_pipeline.pyNext, we define a function for parsing the command line arguments:
%%writefile -a hello_world_pipeline.py
def parse_args ():
"""Parses input arguments"""
parser = argparse.ArgumentParser()
parser.add_argument (
"--config-path",
type=str,
default="pipeline_input.json",
help="Path to config file specifying pipeline input parameters.",
)
parser.add_argument (
"--experiment-name",
type=str,
default="hello-world-experiment",
help="Name of experiment.",
)
args = parser.parse_args()
print ("Running hello-world pipeline with args", args)
return args
And finally, we write our main function which simply calls the argument parser and calls run_pipeline with the parsed arguments:
%%writefile -a hello_world_pipeline.py
def main ():
"""Parses arguments and runs pipeline"""
args = parse_args ()
run_pipeline (
args.config_path,
args.experiment_name,
)
# -------------------------------------------------------------------------------------
# -------------------------------------------------------------------------------------
if __name__ == "__main__":
main ()This is how the pipeline can be run from ipython, and similarly from the command line:
%run hello_world_pipeline.pyFound the config file in: /config.jsonRunning hello-world pipeline with args Namespace(config_path='pipeline_input.json', experiment_name='hello-world-experiment')Class AutoDeleteSettingSchema: This is an experimental class, and may change at any time. Please see https://aka.ms/azuremlexperimental for more information.
Class AutoDeleteConditionSchema: This is an experimental class, and may change at any time. Please see https://aka.ms/azuremlexperimental for more information.
Class BaseAutoDeleteSettingSchema: This is an experimental class, and may change at any time. Please see https://aka.ms/azuremlexperimental for more information.
Class IntellectualPropertySchema: This is an experimental class, and may change at any time. Please see https://aka.ms/azuremlexperimental for more information.
Class ProtectionLevelSchema: This is an experimental class, and may change at any time. Please see https://aka.ms/azuremlexperimental for more information.
Class BaseIntellectualPropertySchema: This is an experimental class, and may change at any time. Please see https://aka.ms/azuremlexperimental for more information.RunId: good_brain_fqtwt959vf
Web View: https://ml.azure.com/runs/good_brain_fqtwt959vf?wsid=/subscriptions/6af6741b-f140-48c2-84ca-027a27365026/resourcegroups/helloworld/workspaces/helloworld
Streaming logs/azureml/executionlogs.txt
========================================
[2024-04-10 09:06:04Z] Submitting 2 runs, first five are: 56673d93:0ab3c91a-266e-42d1-964b-af6cd9a5a8a9,9dc0f6c7:2a6af947-815b-4014-951e-0a66d370a79b
[2024-04-10 09:07:08Z] Completing processing run id 0ab3c91a-266e-42d1-964b-af6cd9a5a8a9.
[2024-04-10 09:07:08Z] Completing processing run id 2a6af947-815b-4014-951e-0a66d370a79b.
[2024-04-10 09:07:08Z] Submitting 1 runs, first five are: 20670901:7fc64bfc-bee0-4238-be3d-fbd26f2304b6
[2024-04-10 09:07:30Z] Completing processing run id 7fc64bfc-bee0-4238-be3d-fbd26f2304b6.
[2024-04-10 09:07:30Z] Submitting 1 runs, first five are: 11635808:7d181008-9749-4ba0-8af0-ee22a9a90a1f
[2024-04-10 09:07:52Z] Completing processing run id 7d181008-9749-4ba0-8af0-ee22a9a90a1f.
Execution Summary
=================
RunId: good_brain_fqtwt959vf
Web View: https://ml.azure.com/runs/good_brain_fqtwt959vf?wsid=/subscriptions/6af6741b-f140-48c2-84ca-027a27365026/resourcegroups/helloworld/workspaces/helloworld
We add the following to our config file:
"name_env"="hello-world",%%writefile hello_world_pipeline.py
# -------------------------------------------------------------------------------------
# Imports
# -------------------------------------------------------------------------------------
# Standard imports
import os
import argparse
import json
# Third-party imports
import pandas as pd
from sklearn.utils import Bunch
# AML imports
from azure.ai.ml import (
command,
dsl,
Input,
Output,
MLClient
)
from azure.ai.ml.entities import Environment
from azure.identity import DefaultAzureCredential
# -------------------------------------------------------------------------------------
# Connection
# -------------------------------------------------------------------------------------
def connect ():
# authenticate
credential = DefaultAzureCredential()
# Get a handle to the workspace
ml_client = MLClient.from_config (
credential=credential,
)
return ml_client
# -------------------------------------------------------------------------------------
# environment
# -------------------------------------------------------------------------------------
def create_env (
ml_client,
image: str="mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04",
conda_file: str="./pipeline.yml",
name_env: str="pipeline",
description_env: str="Pipeline environment",
):
"Creates environment in AML workspace"
env = Environment (
image=image,
conda_file=conda_file,
name=name_env,
description=description_env,
)
ml_client.environments.create_or_update (env)
# -------------------------------------------------------------------------------------
# connect and setup
# -------------------------------------------------------------------------------------
def connect_setup_and_run (
pipeline_object,
experiment_name: str="pipeline experiment",
compute_name: str="jaumecpu",
image: str="mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04",
conda_file: str="./pipeline.yml",
name_env: str="pipeline",
description_env: str="Pipeline environment",
):
"""Does all the setup required to run the pipeline.
This includes: connecting, creating environment, indicating our compute instance,
creating and running the pipeline.
"""
# connect
ml_client = connect ()
# create env
create_env (
ml_client,
image=image,
conda_file=conda_file,
name_env=name_env,
description_env=description_env,
)
# compute
pipeline_object.settings.default_compute = compute_name
# create pipeline and run
pipeline_job = ml_client.jobs.create_or_update(
pipeline_object,
# Project's name
experiment_name=experiment_name,
)
# ----------------------------------------------------
# Pipeline running
# ----------------------------------------------------
ml_client.jobs.stream(pipeline_job.name)
def read_config (config_path: str):
# Read config json file
with open (config_path,"rt") as config_file:
config = json.load (config_file)
# Convert config dictionary into a Bunch object.
# This allows to get access to fields as object attributes
# Which I find more convenient.
config = Bunch (**config)
return config
# -------------------------------------------------------------------------------------
# Pipeline running
# -------------------------------------------------------------------------------------
def run_pipeline (
config_path: str="./pipeline_input.json",
experiment_name="hello-world-experiment",
):
# read config
config = read_config (config_path)
# Pipeline definition
@dsl.pipeline(
description="E2E hello world pipeline with input",
)
def three_components_pipeline(
# Preprocessing component parameters, first component:
preprocessing_training_input_file: str,
preprocessing_training_output_filename: str,
x: int,
# Preprocessing component parameters, second component:
preprocessing_test_input_file: str,
preprocessing_test_output_filename: str,
# Training component parameters:
training_output_filename: str,
# Inference component parameters:
inference_output_filename: str,
):
"""
Third pipeline: preprocessing, training and inference.
Parameters
----------
preprocessing_training_input_file: str
Path to file containing training data to be preprocessed.
preprocessing_training_output_filename: str
Name of file containing the preprocessed, training data.
x: int
Number to add to input data for preprocessing it.
preprocessing_test_input_file: str
Path to file containing test data to be preprocessed.
preprocessing_test_output_filename: str
Name of file containing the preprocessed, test data.
training_output_filename: str
Name of file containing the trained model.
inference_output_filename: str
Name of file containing the output data with inference results.
name_env: str
Name of environment to use.
"""
print (f"using {config.name_env}@latest")
# -------------------------------------------------------------------------------------
# Preprocessing
# -------------------------------------------------------------------------------------
# Interface
preprocessing_component = command(
inputs=dict(
input_file=Input (type="uri_file"),
x=Input (type="number"),
output_filename=Input (type="string"),
),
outputs=dict(
output_folder=Output (type="uri_folder"),
),
code=f"./preprocessing/", # location of source code: in this case, the root folder
command="python preprocessing.py "
"--input_file ${{inputs.input_file}} "
"-x ${{inputs.x}} "
"--output_folder ${{outputs.output_folder}} "
"--output_filename ${{inputs.output_filename}}",
environment=f"{config.name_env}@latest",
display_name="Pre-processing",
)
# Instantiation
preprocessing_training_job = preprocessing_component(
input_file=preprocessing_training_input_file,
#output_folder: automatically determined
output_filename=preprocessing_training_output_filename,
x=x,
)
preprocessing_test_job = preprocessing_component(
input_file=preprocessing_test_input_file,
#output_folder: automatically determined
output_filename=preprocessing_test_output_filename,
x=x,
)
# -------------------------------------------------------------------------------------
# Training component
# -------------------------------------------------------------------------------------
# Interface
training_component = command(
inputs=dict(
input_folder=Input (type="uri_folder"),
input_filename=Input (type="string"),
output_filename=Input (type="string"),
),
outputs=dict(
output_folder=Output (type="uri_folder"),
),
code=f"./training/", # location of source code: in this case, the root folder
command="python training.py "
"--input_folder ${{inputs.input_folder}} "
"--input_filename ${{inputs.input_filename}} "
"--output_folder ${{outputs.output_folder}} "
"--output_filename ${{inputs.output_filename}}",
environment=f"{config.name_env}@latest",
display_name="Training",
)
# Instantiation
training_job = training_component(
input_folder=preprocessing_training_job.outputs.output_folder,
input_filename=preprocessing_training_output_filename,
#output_folder: automatically determined
output_filename=training_output_filename,
)
# -------------------------------------------------------------------------------------
# Inference
# -------------------------------------------------------------------------------------
# Interface
inference_component = command(
inputs=dict(
preprocessed_input_folder=Input (type="uri_folder"),
preprocessed_input_filename=Input (type="string"),
model_input_folder=Input (type="uri_folder"),
model_input_filename=Input (type="string"),
output_filename=Input (type="string"),
),
outputs=dict(
output_folder=Output (type="uri_folder"),
),
code=f"./inference/", # location of source code: in this case, the root folder
command="python inference.py "
"--preprocessed_input_folder ${{inputs.preprocessed_input_folder}} "
"--preprocessed_input_filename ${{inputs.preprocessed_input_filename}} "
"--model_input_folder ${{inputs.model_input_folder}} "
"--model_input_filename ${{inputs.model_input_filename}} "
"--output_folder ${{outputs.output_folder}} "
"--output_filename ${{inputs.output_filename}} ",
environment=f"{config.name_env}@latest",
display_name="inference",
)
# Instantiation
inference_job = inference_component(
preprocessed_input_folder=preprocessing_test_job.outputs.output_folder,
preprocessed_input_filename=preprocessing_test_output_filename,
model_input_folder=training_job.outputs.output_folder,
model_input_filename=training_output_filename,
#output_folder: automatically determined
output_filename=inference_output_filename,
)
# Build pipeline
three_components_pipeline_object = three_components_pipeline(
# first preprocessing component
preprocessing_training_input_file=Input(type="uri_file", path=config.preprocessing_training_input_file),
preprocessing_training_output_filename=config.preprocessing_training_output_filename,
x=config.x,
# second preprocessing component
preprocessing_test_input_file=Input(type="uri_file", path=config.preprocessing_test_input_file),
preprocessing_test_output_filename=config.preprocessing_test_output_filename,
# Training component parameters:
training_output_filename=config.training_output_filename,
# Inference component parameters:
inference_output_filename=config.inference_output_filename,
)
connect_setup_and_run (
three_components_pipeline_object,
experiment_name=experiment_name,
compute_name=config.compute_name,
image=config.image,
conda_file=config.conda_file,
name_env=config.name_env,
description_env=config.description_env,
)
# -------------------------------------------------------------------------------------
# Parsing
# -------------------------------------------------------------------------------------
def parse_args ():
"""Parses input arguments"""
parser = argparse.ArgumentParser()
parser.add_argument (
"--config-path",
type=str,
default="pipeline_input.json",
help="Path to config file specifying pipeline input parameters.",
)
parser.add_argument (
"--experiment-name",
type=str,
default="hello-world-experiment",
help="Name of experiment.",
)
args = parser.parse_args()
print ("Running hello-world pipeline with args", args)
return args
# -------------------------------------------------------------------------------------
# main
# -------------------------------------------------------------------------------------
def main ():
"""Parses arguments and runs pipeline"""
args = parse_args ()
run_pipeline (
args.config_path,
args.experiment_name,
)
# -------------------------------------------------------------------------------------
# -------------------------------------------------------------------------------------
if __name__ == "__main__":
main ()Overwriting hello_world_pipeline.py%run hello_world_pipeline.pyFound the config file in: /config.jsonRunning hello-world pipeline with args Namespace(config_path='pipeline_input.json', experiment_name='hello-world-experiment')
using hello-world@latest
RunId: lucid_napkin_t6nkwzqqfx
Web View: https://ml.azure.com/runs/lucid_napkin_t6nkwzqqfx?wsid=/subscriptions/6af6741b-f140-48c2-84ca-027a27365026/resourcegroups/helloworld/workspaces/helloworld
Streaming logs/azureml/executionlogs.txt
========================================
[2024-04-10 09:42:21Z] Submitting 2 runs, first five are: a13baad8:2e78988c-ec3d-42c7-ad94-54617bee7252,e9a47e09:b17a6162-ff6c-48a3-af00-becc887c58d8
[2024-04-10 09:42:43Z] Completing processing run id 2e78988c-ec3d-42c7-ad94-54617bee7252.
[2024-04-10 09:42:54Z] Completing processing run id b17a6162-ff6c-48a3-af00-becc887c58d8.
[2024-04-10 09:42:55Z] Submitting 1 runs, first five are: 9e02ee11:40379116-e551-49fa-b02b-8af7678e75e4
[2024-04-10 09:43:16Z] Completing processing run id 40379116-e551-49fa-b02b-8af7678e75e4.
[2024-04-10 09:43:17Z] Submitting 1 runs, first five are: 01e4367a:e69290f9-ce7c-4946-a3b9-db4b0ab5ad0a
[2024-04-10 09:43:38Z] Completing processing run id e69290f9-ce7c-4946-a3b9-db4b0ab5ad0a.
Execution Summary
=================
RunId: lucid_napkin_t6nkwzqqfx
Web View: https://ml.azure.com/runs/lucid_napkin_t6nkwzqqfx?wsid=/subscriptions/6af6741b-f140-48c2-84ca-027a27365026/resourcegroups/helloworld/workspaces/helloworld
def mydec (f):
def mywrap (*args, **kwargs):
print ("hello")
f()
print ("bye")
return mywrap
def outerf ():
x = 3
@mydec
def myf ():
print (f"myf: {x}")
myf()outerf()hello
myf: 3
bye'${{parent.inputs.name_env}}'from hello_world_pipeline import connect, create_env, read_configml_client = connect ()Found the config file in: /config.jsonconfig = read_config ("./pipeline_input.json")create_env (
ml_client,
config.image,
config.conda_file,
config.name_env,
config.description_env,
)Found the config file in: /config.jsonx=ml_client.environments.get (config.name_env, version="1")x.name'hello-world'config.name_env'hello-world'x.version'1'MLFlow automatically creates job in AML.
@command_component decorator, see https://learn.microsoft.com/en-us/azure/machine-learning/how-to-create-component-pipeline-python?view=azureml-api-2#create-components-for-building-pipeline